为什么一夜之间大家都在做 CLI?
为什么一夜之间大家都在做 CLI?飞书、Google、Stripe、ElevenLabs、网易云音乐。 最近几个月,一群看起来毫不相关的公司不约而同做了同一件事:发布 CLI 工具。
来自主题: AI技术研报
7861 点击 2026-03-30 09:56
 搜索
搜索
飞书、Google、Stripe、ElevenLabs、网易云音乐。 最近几个月,一群看起来毫不相关的公司不约而同做了同一件事:发布 CLI 工具。

想象一下这个场景:你在地铁上刷着 Slack,看到一个需要修复的 bug。你点一个 emoji 表情,等到了办公室,代码已经写好、测试通过,Pull Request 等着你审查。这不是科幻小说,这是 Stripe 工程师每天的真实工作状态。

就在刚刚,NeurIPS在X上公开道歉,并表明: 我们已经更新了手册,与ACM、IEEE以及其他国际会议和往届NeurIPS的投稿规则保持一致。与往年一样,NeurIPS欢迎所有符合合规要求的机构和个人提交论文。

中国是NeurIPS最大的「粮仓」,却被新规一刀切断。CCF回应只有一句话:全体中国计算机领域科学家拒绝为其服务!更狠的还在后面:如不纠正错误,直接移出CCF推荐目录。

NeurIPS 不再让华为等机构投稿了?这个消息确实出自 NeurIPS 官方文件。在本届大会征稿通知的页面,藏着一个「MainTrackHandbook」的链接:打开链接,就能看到大会关于今年投稿的一些说明。
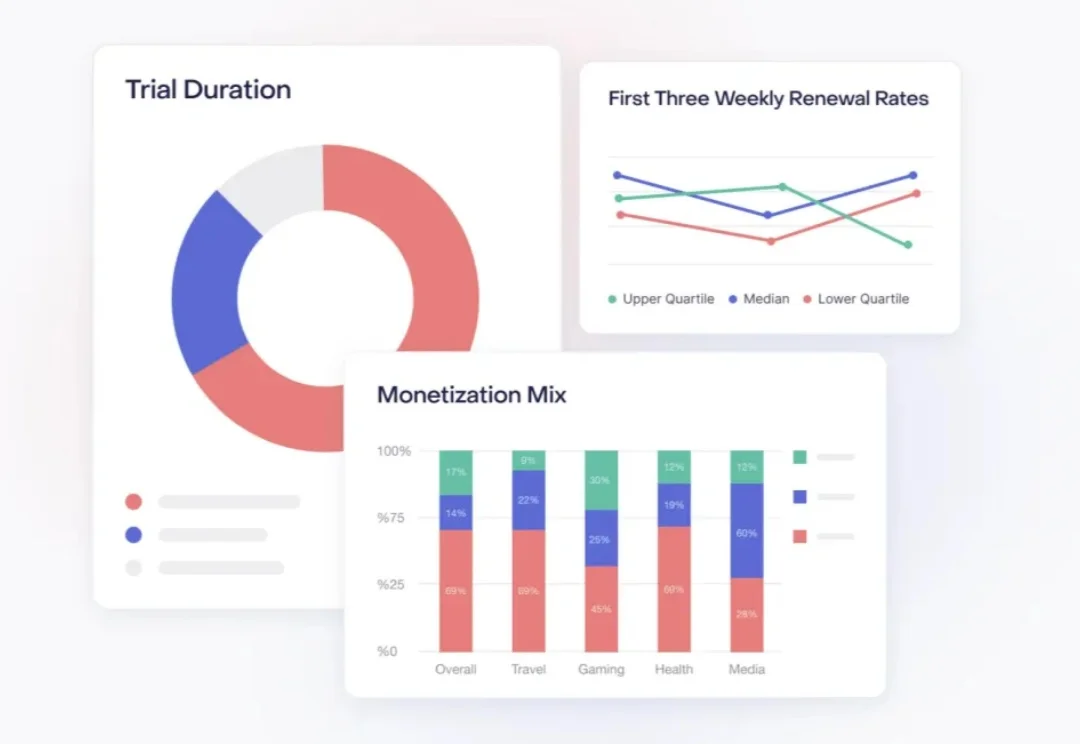
打开手机的订阅管理页面,我数了一下:过去十二个月里,我为各种 AI 应用付过费的数量是七个。目前还在续费的,两个。
速度、质量、管线可用性,是 AI 3D 生成领域公认的不可能三角。三件事,从来没有同时成立过。直到现在。VAST 最新发布的 Tripo P1.0,首次在原生三维空间中实现概率生成,2 秒内即可输出专业建模师级别的 3D 资产,效率较现有方案提升百倍以上。

用强化学习微调扩散模型,还有更好的办法吗?

较真还得是程序员。
AI写代码,这次玩大了。 Cursor创始人宣布一项疯狂实验的结果:让数百个AI智能体连续跑了整整一周,从零开始,硬生生造出了一个可用的Web浏览器。项目代号FastRender,产出超过300万行代码,核心是一个用Rust从头写的渲染引擎,甚至还自带一个定制的JavaScript虚拟机。