
3个月连融5亿,具身智能公司「极佳视界」完成2亿元A2轮融资,推出物理AGI的原生模型与原生本体
3个月连融5亿,具身智能公司「极佳视界」完成2亿元A2轮融资,推出物理AGI的原生模型与原生本体目标物理世界的“ChatGPT时刻”。
来自主题: AI资讯
6627 点击 2025-12-08 15:17
 搜索
搜索
目标物理世界的“ChatGPT时刻”。

据知情人士透露,开发客户服务人工智能的德国初创公司Parloa正在寻求新一轮融资,估值将较今年5月大幅提升。这家在德国和纽约设有办公室的公司,已与包括General Catalyst在内的投资者进行了洽谈,寻求筹集约2亿美元的新资金。知情人士称,Parloa正在讨论的潜在估值区间约为20亿至30亿美元。
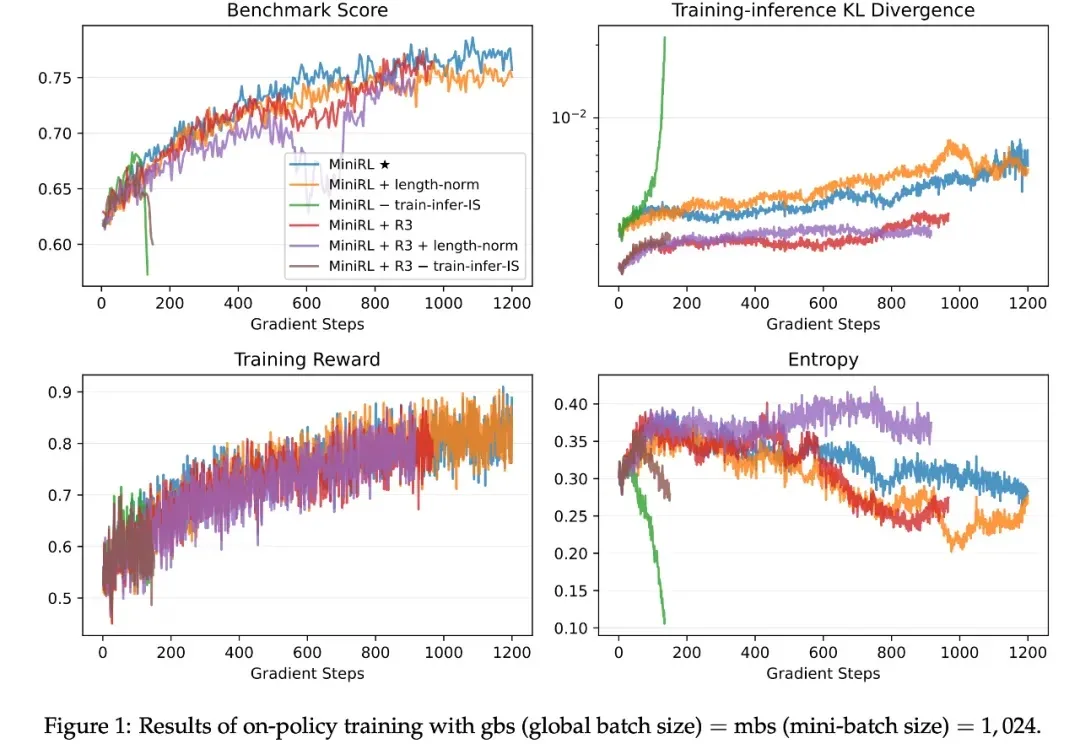
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
2025年,AI大模型的竞争焦点正在发生根本性转移。

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。

Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。

昨日,有位推特博主晒出了国内几大开源模型在轻量级软件工程 Agent 基准测试 mini-SWE-agent 上的成绩。该基准主要测试大模型在真实软件开发任务中的多步推理、环境交互和工程化能力。

DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。
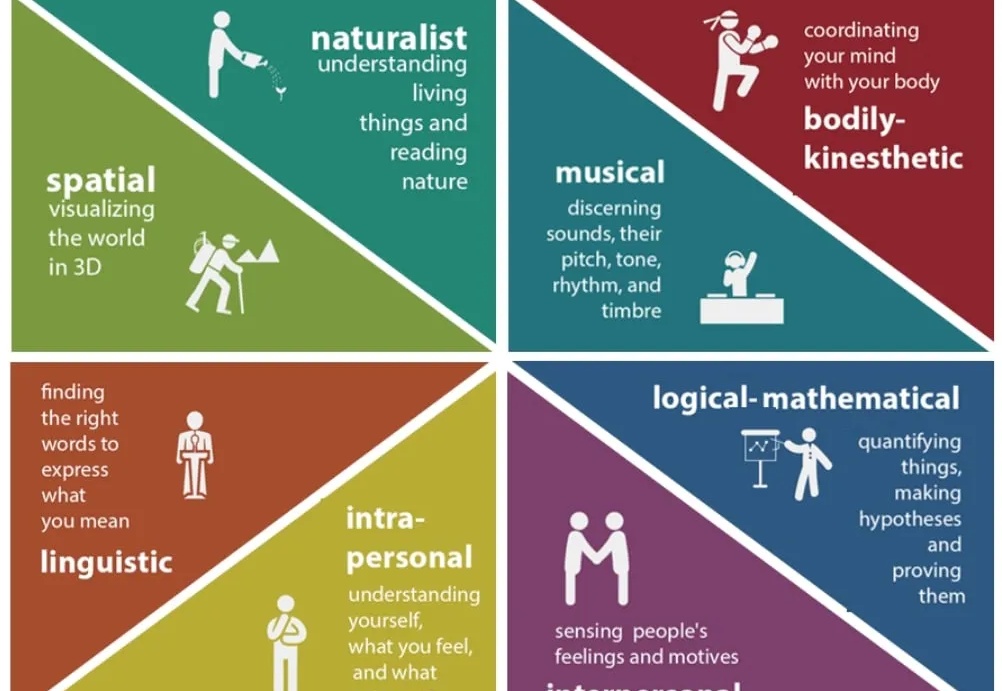
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。