看完 Karpathy 的推文,我决定用 AI 给自己建一座「人生碎片 Wiki 百科」|附保姆级教程、已开源
看完 Karpathy 的推文,我决定用 AI 给自己建一座「人生碎片 Wiki 百科」|附保姆级教程、已开源前天刷 X,刷到一个叫 Farza 的老哥,做了件牛 X 的事。
来自主题: AI技术研报
8277 点击 2026-04-10 09:09
 搜索
搜索
前天刷 X,刷到一个叫 Farza 的老哥,做了件牛 X 的事。
我确实对运行 OpenClaw 持相当怀疑的态度。…… 整个生态给人的感觉就像是一个彻底的狂野西部,在安全性上简直是一场噩梦。 —— Andrej Karpathy
AI圈的节奏已经快到让人产生幻觉了。

最近,飞书、钉钉、企业微信接连推出 CLI,智能体生态战役再次打响。
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。
Claude Code正在光速进化为Claude Claw。
不知道大家还记不记得,去年 3 月,AI 大牛 Karpathy 发过一条推文。大体意思是说:现在的大多数内容仍然是为人类编写的,但未来,读取这些内容的可能就不是人类而是 AI 了。因此,从现在开始,我们就要考虑怎么把文档写得对 AI 更友好。

Karpathy给一支平均年龄25岁的「叛军」站台,红杉和GV连眼都不眨就拍出1.8亿美金。这群人放话:要么把效率干得比人脑高10倍,要么看着AI把地球烧干!

一次只持续了不到1小时的投毒事件,撕开了AI基础设施「信任链」的致命裂缝。更魔幻的是,全行业逃过一劫,居然靠黑客自己写出bug。
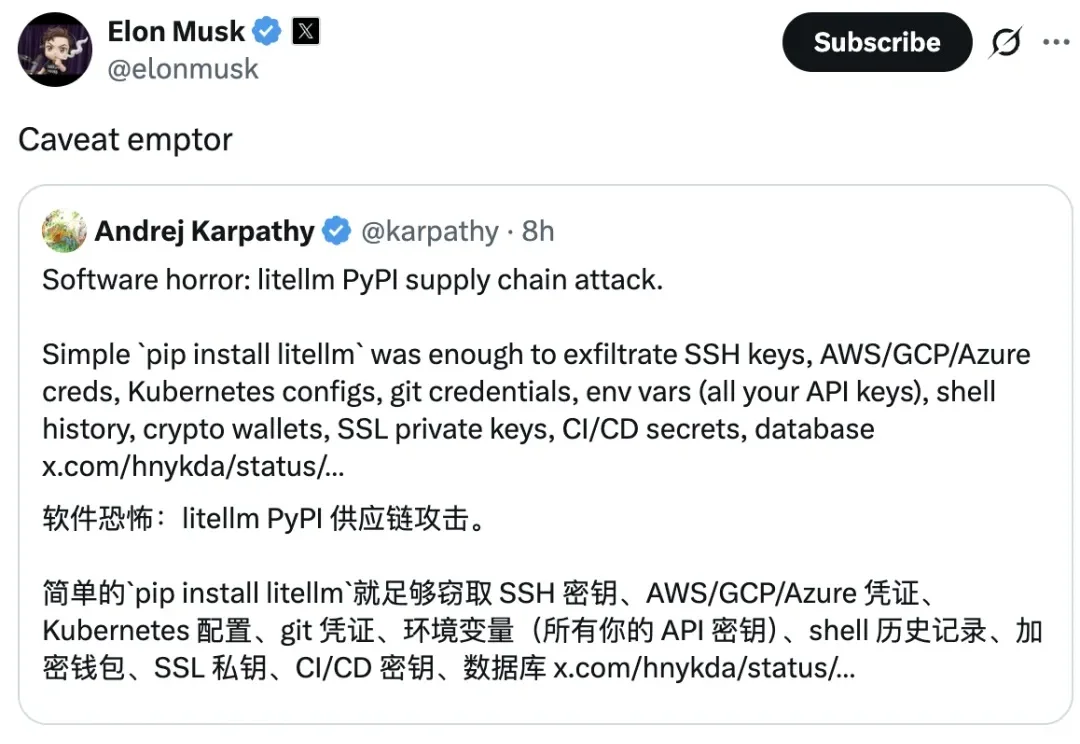
这是一件极其严肃的软件安全事件。