
大模型微调范式认知再被颠覆?UIUC、Amazon团队最新研究指出SFT灾难性遗忘问题或被误解
大模型微调范式认知再被颠覆?UIUC、Amazon团队最新研究指出SFT灾难性遗忘问题或被误解在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。
来自主题: AI技术研报
8475 点击 2025-10-24 10:13
 搜索
搜索
在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
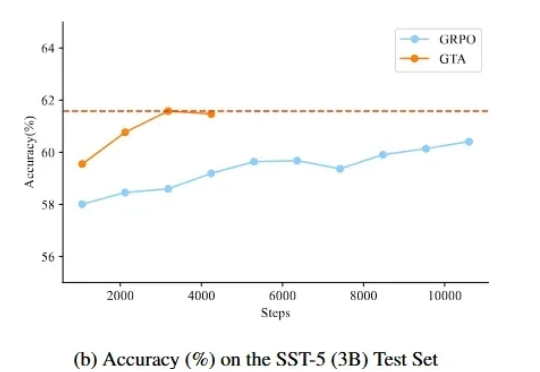
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
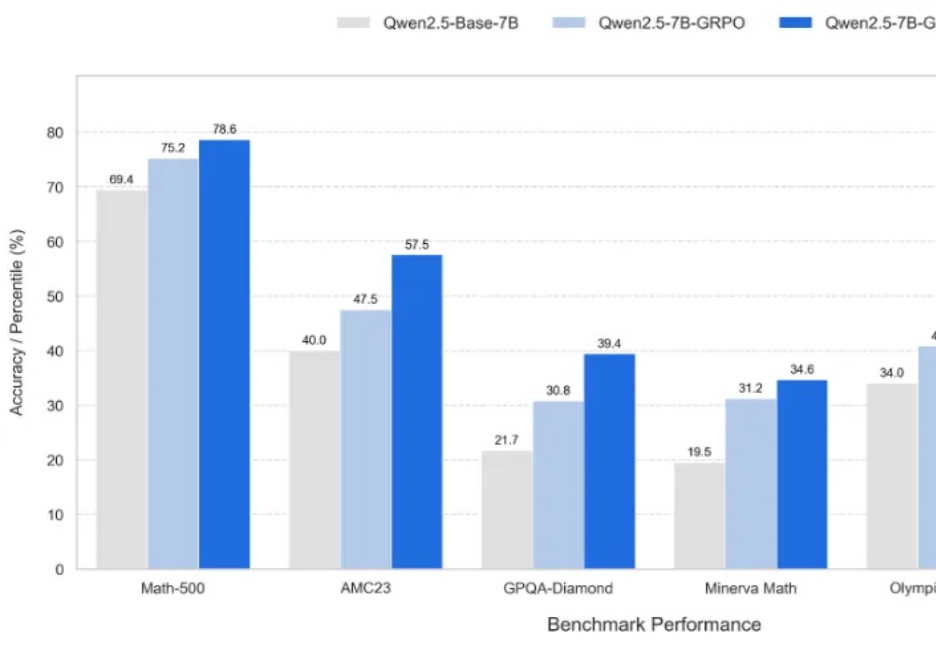
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
多模态推理,也可以讲究“因材施教”?
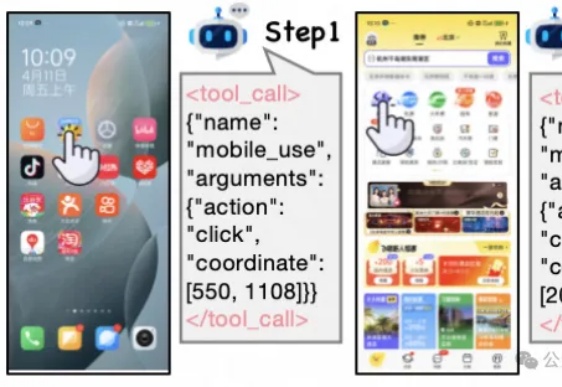
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。
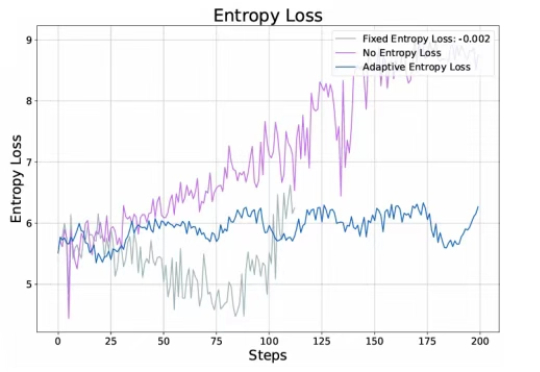
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。
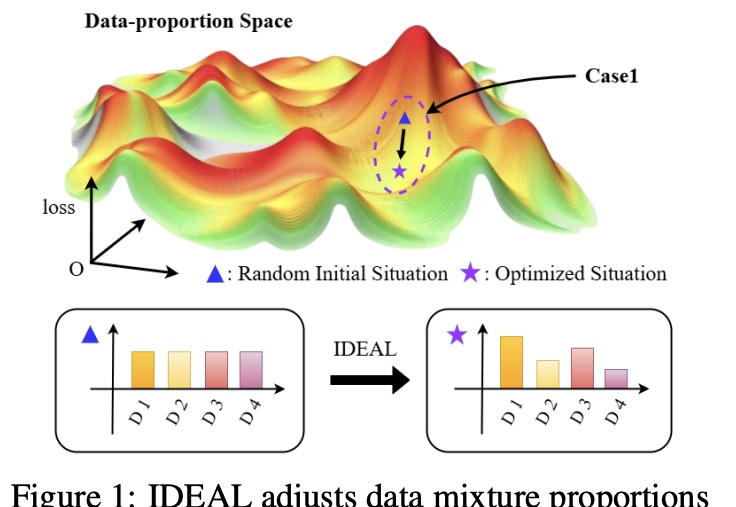
大幅缓解LLM偏科,只需调整SFT训练集的组成。