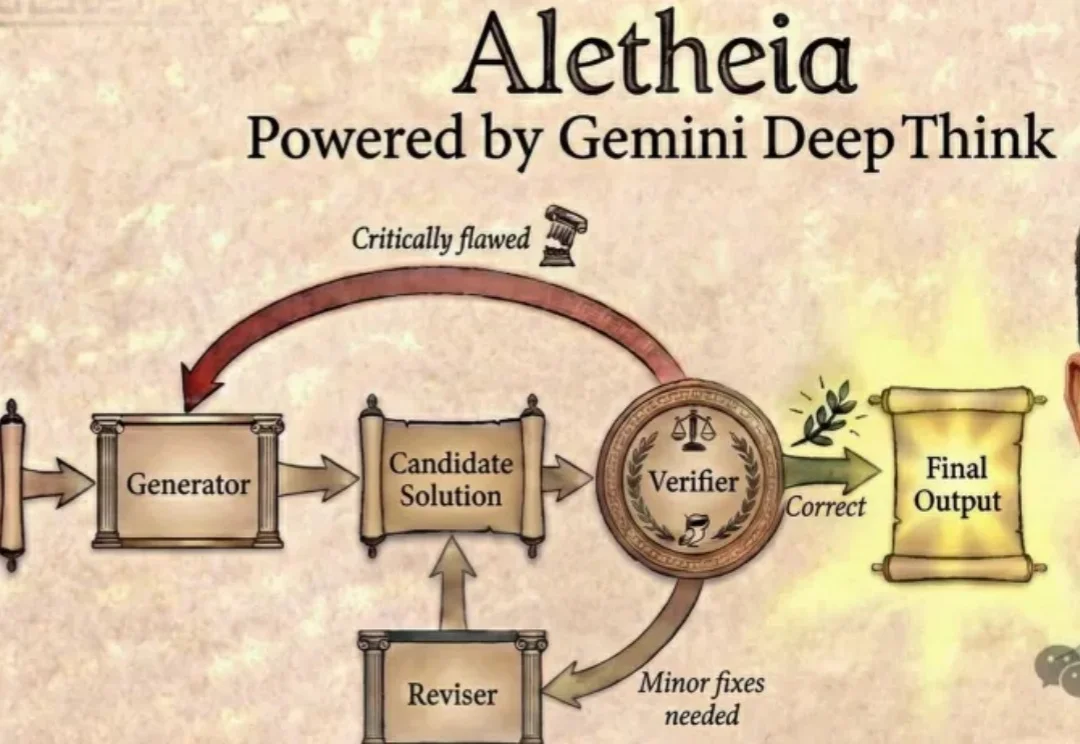
谷歌AI连发6篇数学论文!Gemini攻入博士级科研,91.9%刷爆SOTA
谷歌AI连发6篇数学论文!Gemini攻入博士级科研,91.9%刷爆SOTA今天,谷歌DeepMind「AI数学家」Aletheia彻底杀疯了,攻克数学猜想,独立写论文。更令人震惊的是,拿下金牌的Gemini一举横扫18大核心科研难题。
来自主题: AI资讯
10417 点击 2026-02-12 10:41
 搜索
搜索
今天,谷歌DeepMind「AI数学家」Aletheia彻底杀疯了,攻克数学猜想,独立写论文。更令人震惊的是,拿下金牌的Gemini一举横扫18大核心科研难题。

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混

2026 刚来到 2 月,无论是底层模型大厂还是初创公司统统加速开卷,其中 Agentic Memory 方向的快速进化更是把大模型的能力上限推向了 NEXT LEVEL!
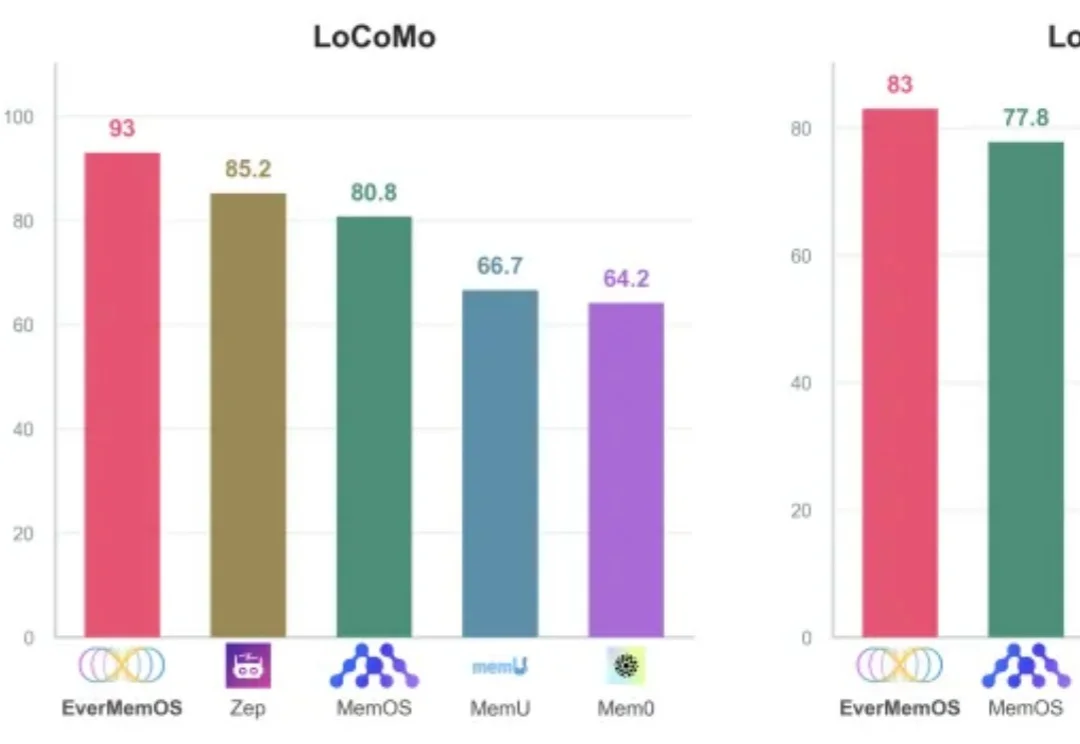
开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。
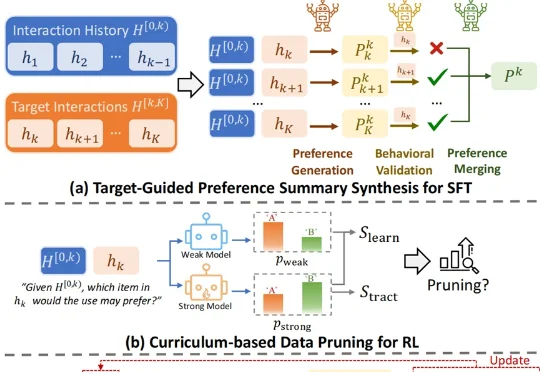
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
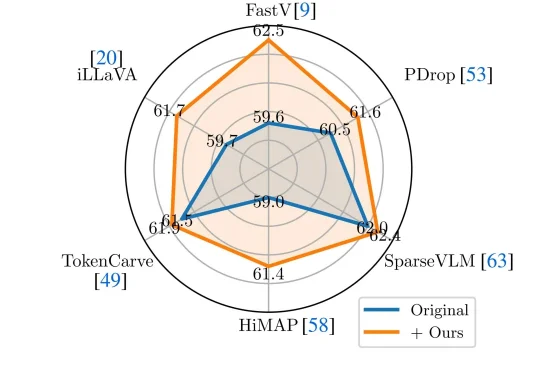
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。
好家伙,AGI真的「Open」了我的生活。(doge)

世界模型迎来高光时刻:谷歌还在闭源,中国团队已经把SOTA级世界模型全面开源了,LingBot-World正面硬刚Genie 3,彻底打破了全球垄断!
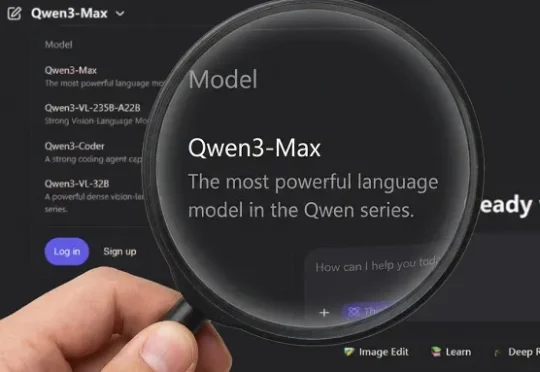
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。