
谁在杀死OpenAI?7年元老出走,Sora沦为弃子,理想主义崩塌
谁在杀死OpenAI?7年元老出走,Sora沦为弃子,理想主义崩塌最新消息显示,奥特曼已将公司核心资源从探索性的长线研究(Blue-sky research)全面倾斜至旗舰产品ChatGPT的工程化改进。这一战略调整,导致包括前研究副总裁Jerry Tworek在内的多位核心元老因理念分歧而心寒出走。
来自主题: AI资讯
9865 点击 2026-02-22 11:19
 搜索
搜索
最新消息显示,奥特曼已将公司核心资源从探索性的长线研究(Blue-sky research)全面倾斜至旗舰产品ChatGPT的工程化改进。这一战略调整,导致包括前研究副总裁Jerry Tworek在内的多位核心元老因理念分歧而心寒出走。

这两天,AI 视频圈被偷摸摸上线的 Seedance 2.0 刷屏了。在 AI 视频领域颇有影响力的博主海辛,在即刻分享了自己对它的观点:「Seedance 2.0 是我 26 年来最大的震撼」、「我觉得它碾压 Sora2」。

如果 2024 年我们还在感叹 Sora 模拟物理世界的真实感,那么在 2026 年的今天,单纯的高清视频生成已不再是终点。
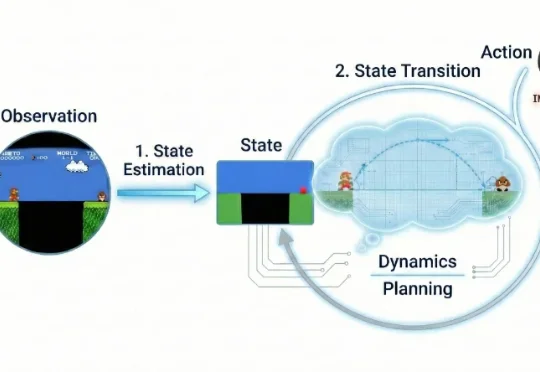
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
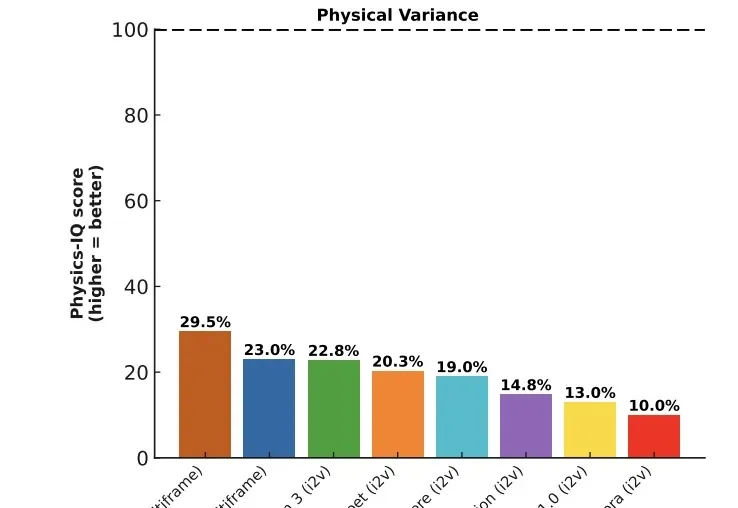
去年下半年,模型界最大的惊喜莫过于Sora 2和Veo 3,他们已经把视频生成推到了新高度:光影完美,纹理细腻,甚至有着很高的时空一致性。
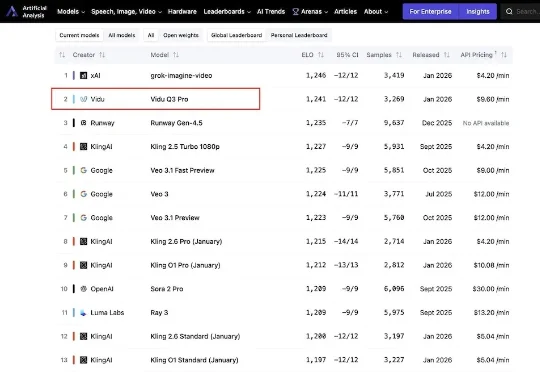
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
打开社交媒体,义乌产的各种小商品下方,经常会出现外国IP的求购留言:“能发英国吗?”“美国可买吗?”几块钱的小商品,一旦搭上跨境快车,就能撬动全球市场。而这也是无数卖家2026年的出海梦想。 从202
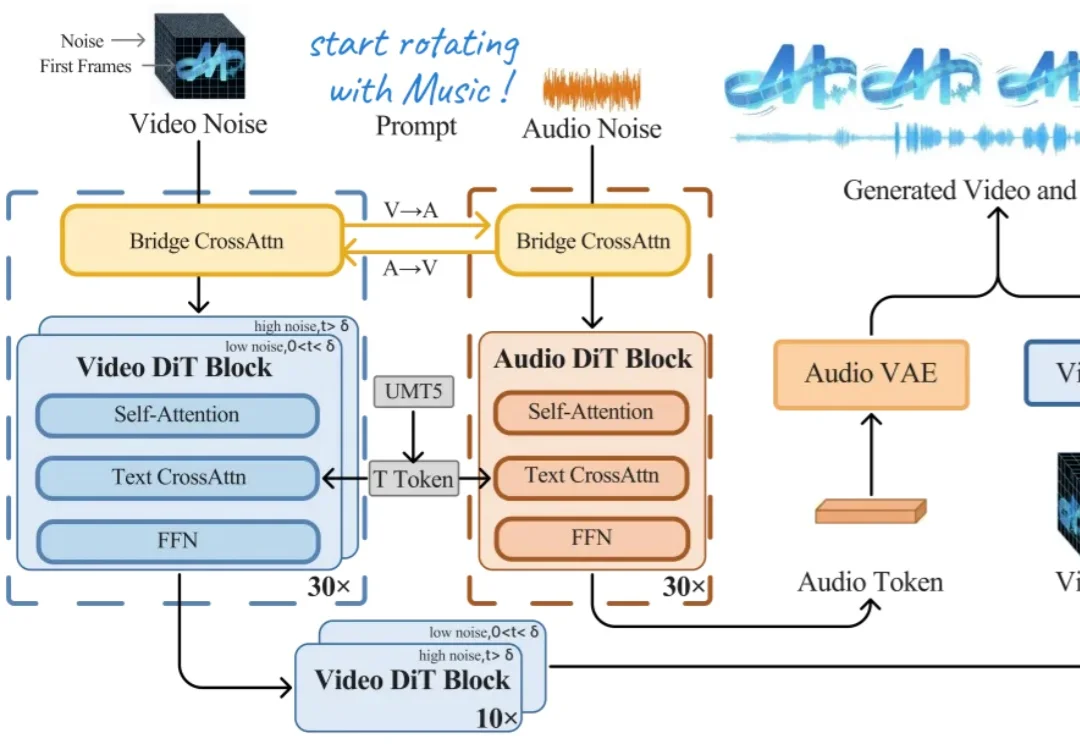
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
你的下一个视频团队,不一定非得是人。

Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。