
视频模型也能推理,Sora2推理能力超过GPT-5
视频模型也能推理,Sora2推理能力超过GPT-5DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试
来自主题: AI技术研报
9146 点击 2025-12-06 10:57
 搜索
搜索
DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试
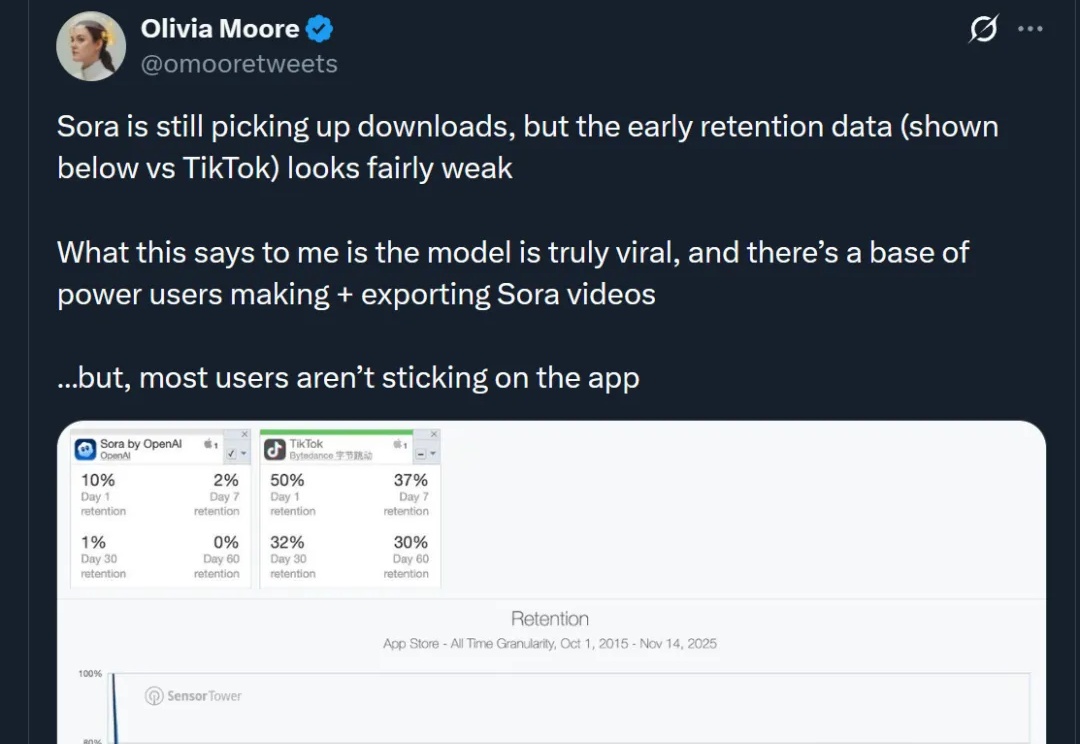
Sora APP,这就凉凉了?!

2025 年,AI 视频又把桌子掀了。手切金属、小猫做饭,甚至是那个火遍全网的「奥特曼宇宙」,对 AI 来说不过是几句 Prompt 的功夫。

刚刚,一个名为 Whisper Thunder (aka) David 的神秘模型登上了 Artificial Analysis 视频榜榜首,超越了 Veo 3、Veo 3.1、Kling 2.5 以及 Sora 2 Pro 等目前市面上所有公开的 AI 视频模型。

在AI数据中心里,数以万计的英伟达H100 GPU,正静静地躺在地上吃灰。这些单价3万美元、被黄仁勋称为「工业黄金」的芯片,本该全速运转,为GPT-5或Sora注入灵魂,但此刻——它们没有电。

To C玩梗是Sora的热闹,用多模态大一统模型服务专业客户,才是AI视频生成的正经生意。

近日,一家名为 CraftStory 的 AI 初创公司推出了 Model 2.0 视频生成系统,凭借可生成长达五分钟的富有表现力、可媲美专业水准、以人为中心的视频,破解了困扰 AI 视频生成行业长久以来的「视频时长」难题,引起热议,并被视为或将是 OpenAI 的 Sora 和 Google 的 Veo 的强有力竞争者。

今年不少出圈的 AI 视频,基本都有一个共同点:套了个熟悉的 IP 壳。
上个月 OpenAI 在发布 Sora 2 的同时将其作为独立应用发布,产品一经上线便登顶苹果应用商店榜首的现象级产品。本篇内容是对 Sora 2 的三位核心负责人的访谈:研发负责人 Bill Peebles、产品负责人 Rohan Sahai 以及工程与产品负责人 Thomas Dimson,Dimson 还参与过 Instagram 产品的搭建。
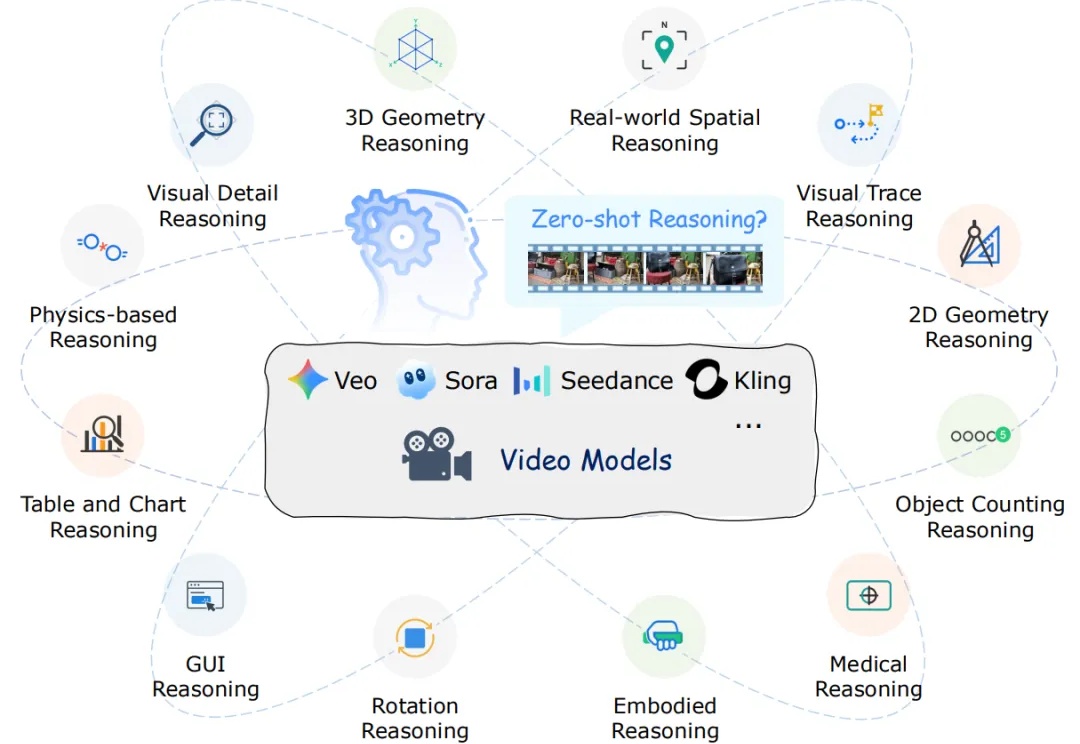
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。