
偶然刷到的一个逆天ElevenLabs开源平替!
偶然刷到的一个逆天ElevenLabs开源平替!订阅了 ElevenLabs 的小伙伴看过来,它的开源平替来了!Chatterbox 是全球首个支持强烈情绪控制的开源TTS 模型,更是号称开源 TTS 中的 SOTA ,由 Resemble AI 推出。
来自主题: AI资讯
8917 点击 2025-09-05 11:35
 搜索
搜索
订阅了 ElevenLabs 的小伙伴看过来,它的开源平替来了!Chatterbox 是全球首个支持强烈情绪控制的开源TTS 模型,更是号称开源 TTS 中的 SOTA ,由 Resemble AI 推出。
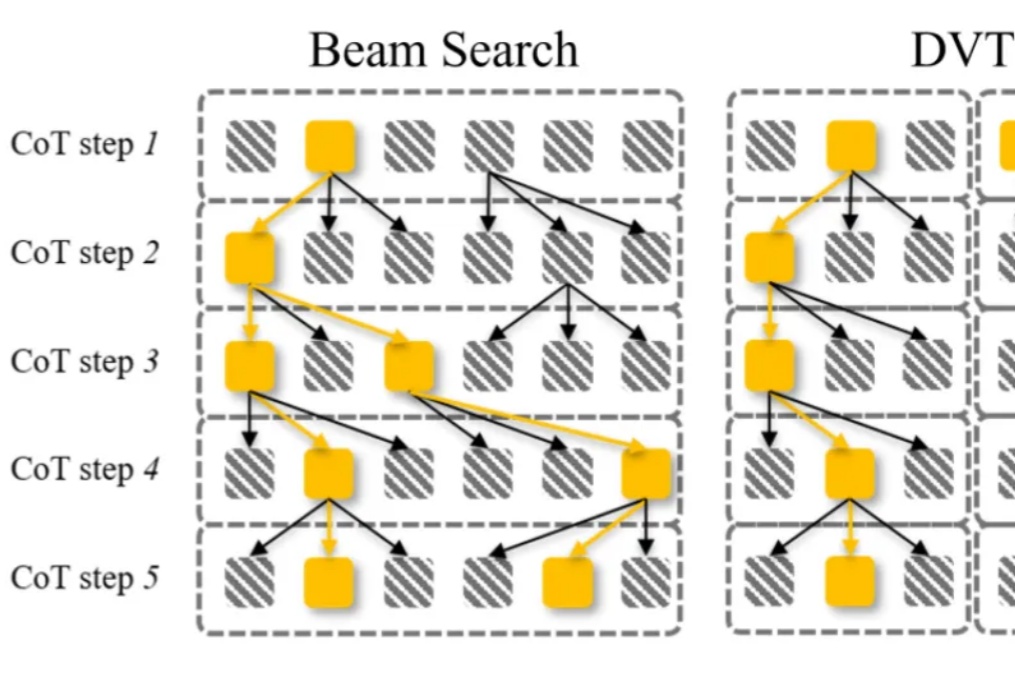
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
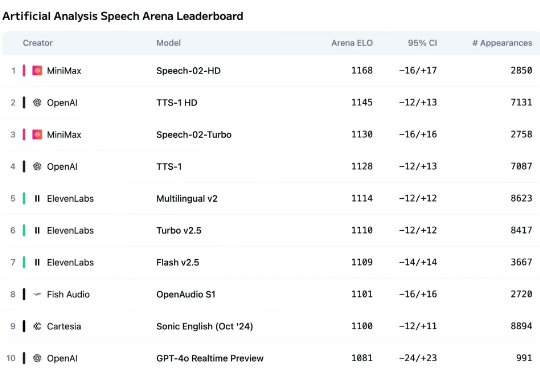
今天,MiniMax发布新一代语音生成模型Speech 2.5,再次刷新全球最强语音模型的上限。
FlowSpeech的开发初衷源于一个感人故事。一位年过八旬的美国老人因长期病痛失去说话能力,但通过AI工具ListenHub继续与他人分享自己的人生经历。这个真实案例启发了开发团队,促使他们研发出专门针对书面语向口语转换的TTS技术解决方案。
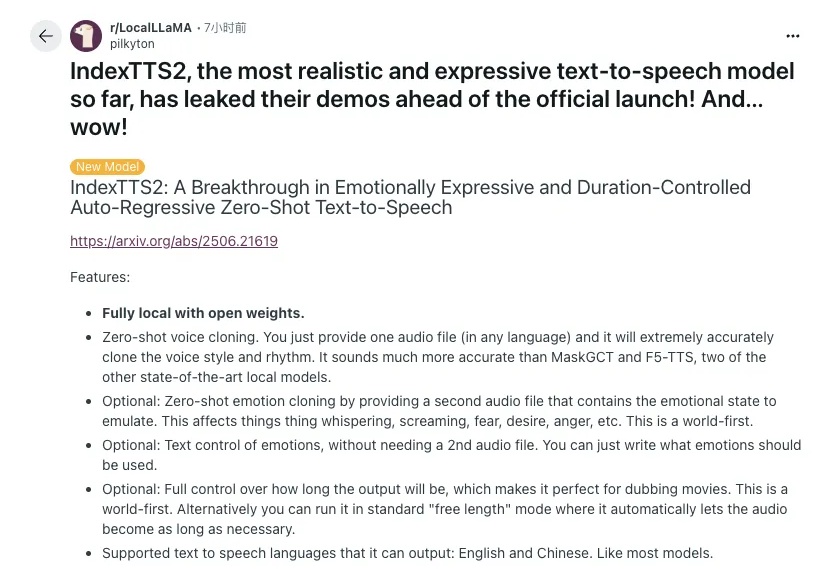
当甄嬛传、让子弹飞全都转英文,会怎样?
最近一个「泄露」的文本转语音模型演示版本在 Reddit 上火了。这个「泄露」的演示视频被网友贴出来后,评论区一片惊呼。
今天咱们再聊聊TTS(文本转语音)这个话题。4月份给大家分享了MiniMax的TTS平台:MiniMax Audio当时我直呼它是最强中文TTS,那篇反响还不错,主要他们Speech-02-HD的效果确实NB

播客、访谈、体育解说、新闻报道和电商直播中,语音对话已经无处不在。 当前的文本到语音(TTS)模型在单句或孤立段落的语音生成效果上取得了令人瞩目的进展,合成语音的自然度、清晰度和表现力都已显著提升,甚至接近真人水平。不过,由于缺乏整体的对话情境,这些 TTS 模型仍然无法合成高质量的对话语音。
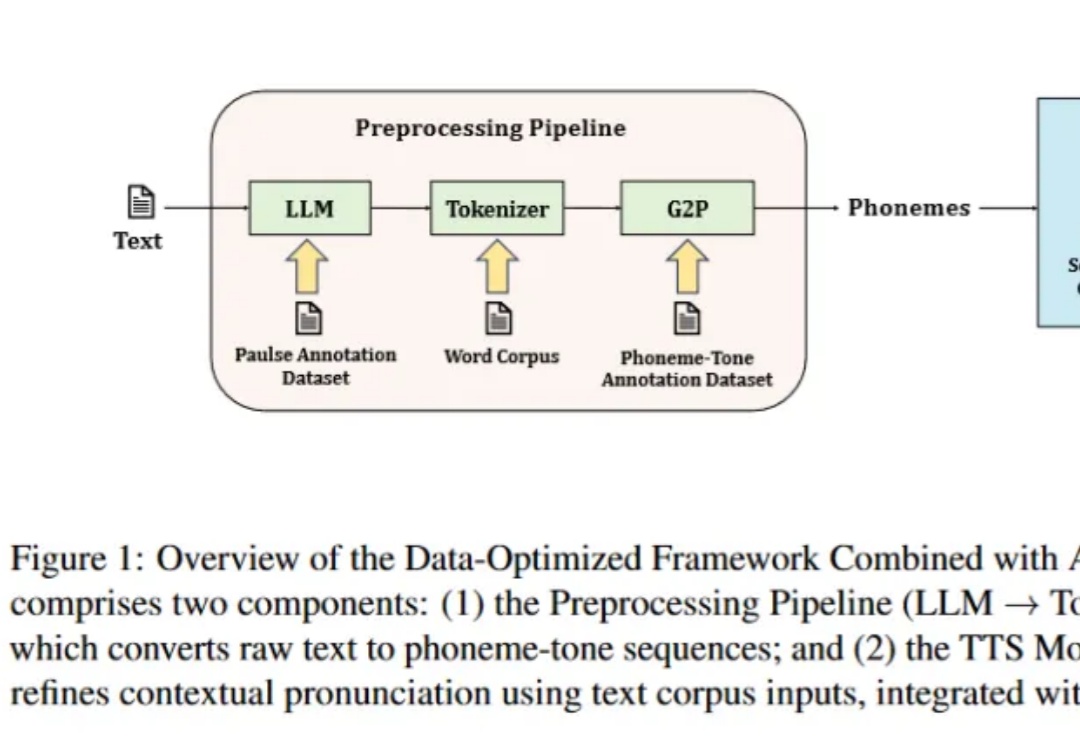
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。
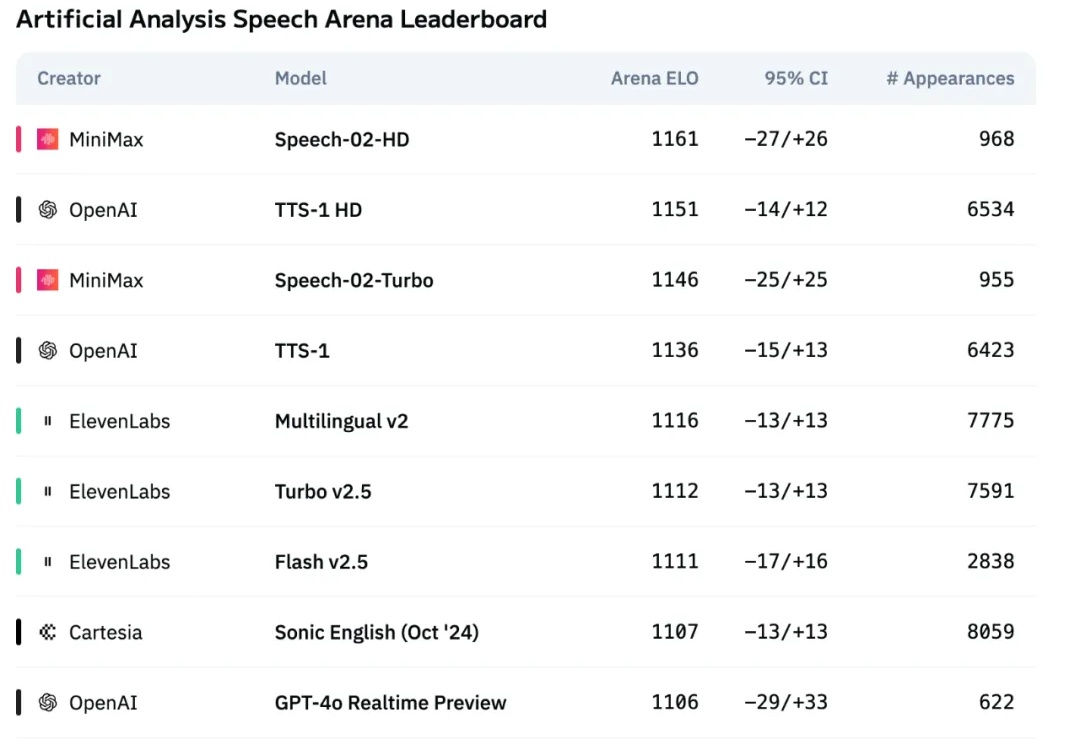
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。