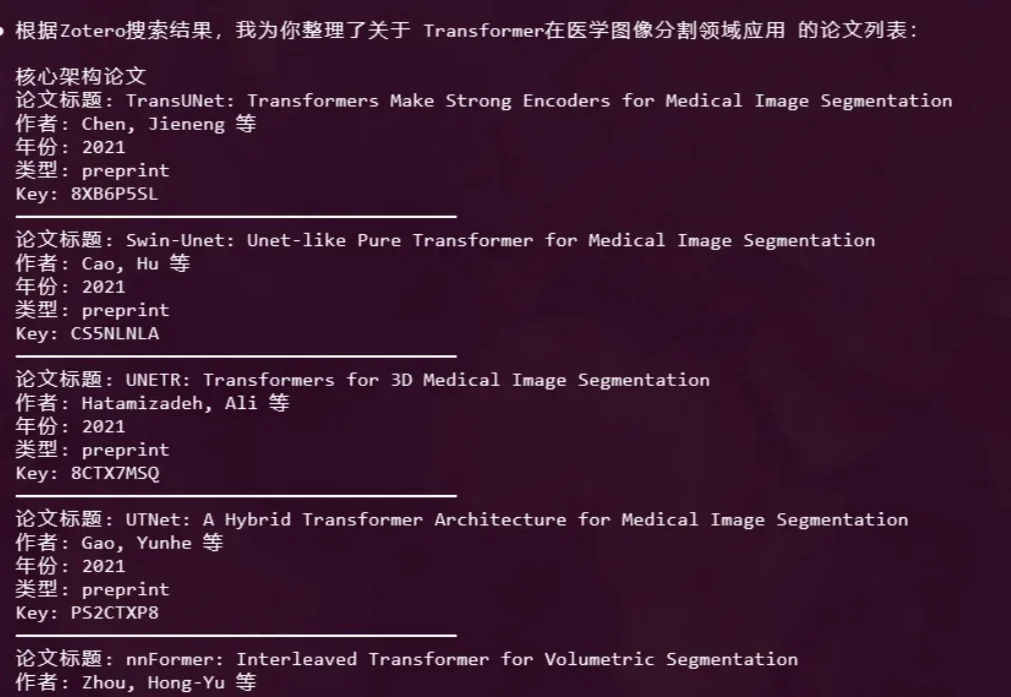
Vibe Researching必备的科研MCP和Skills,实现10倍学术产出
Vibe Researching必备的科研MCP和Skills,实现10倍学术产出大家好,我是鲁工。 Vibe Coding概念火了之后,顺带在很多领域兴起了Vibe的潮流。比如Vibe PPT、Vibe Video,以及我今天要聊的Vibe Researching。
来自主题: AI技术研报
11827 点击 2026-02-02 10:03
 搜索
搜索
大家好,我是鲁工。 Vibe Coding概念火了之后,顺带在很多领域兴起了Vibe的潮流。比如Vibe PPT、Vibe Video,以及我今天要聊的Vibe Researching。
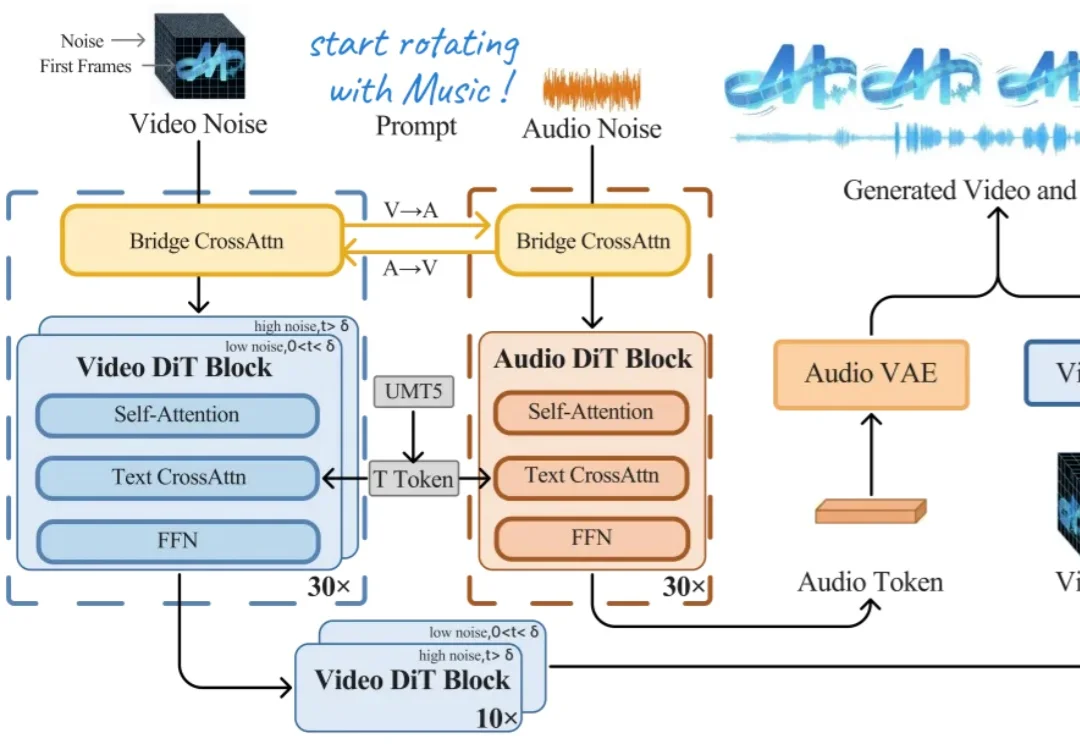
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。

在当前的AI Research浪潮中,Autonomous Agents已经改变了我们获取信息的方式——从被动接收到主动检索。
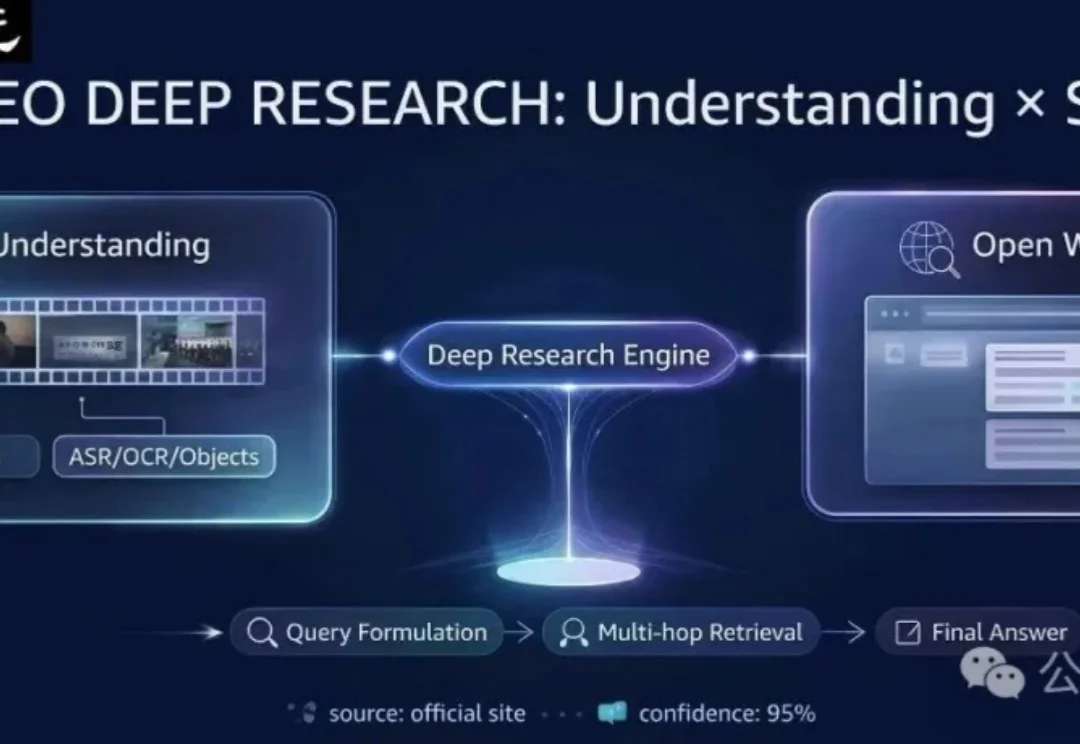
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。

感谢AI!

从ChatGPT爆火以后,就总有“AI太牛了,自己是不是要失业了”等等类似的声音出现。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
2025最后几天,是时候来看点年度宝藏论文了。

在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。
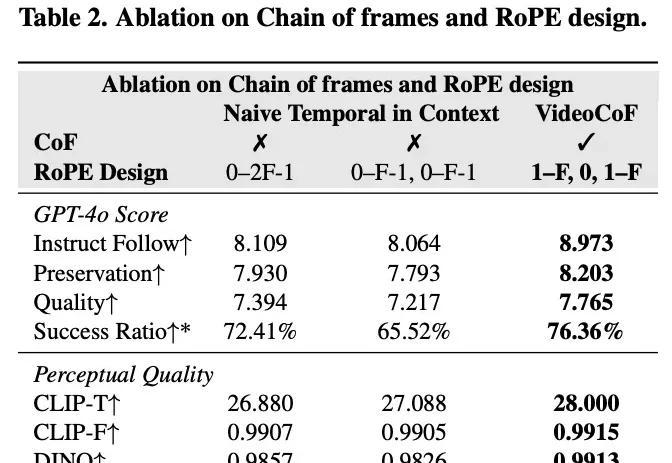
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!