Codex 一键省 Token 大法,亲测有效
Codex 一键省 Token 大法,亲测有效最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。这个项目的介绍图也特别有意思,在项目描述里写着,你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。
来自主题: AI资讯
9397 点击 2026-06-29 11:41
 搜索
搜索
最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。这个项目的介绍图也特别有意思,在项目描述里写着,你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。

最近,这个AI穿越Vlog刷爆全网!第一视角空降古罗马、泰坦尼克号,逼真到窒息。历史次元壁被打破的那一瞬间,很多「亲历现场」的观众,开始落泪了。

什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。

2026年6月,全球AI算力产业最焦虑的事情,不是英伟达Rubin能不能按时出货,也不是台积电CoWoS产能够不够——而是一台大多数人根本没听说过的机器:日本丰田工业的喷气织布机。

2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。

阿辉又跟我们吐槽了。
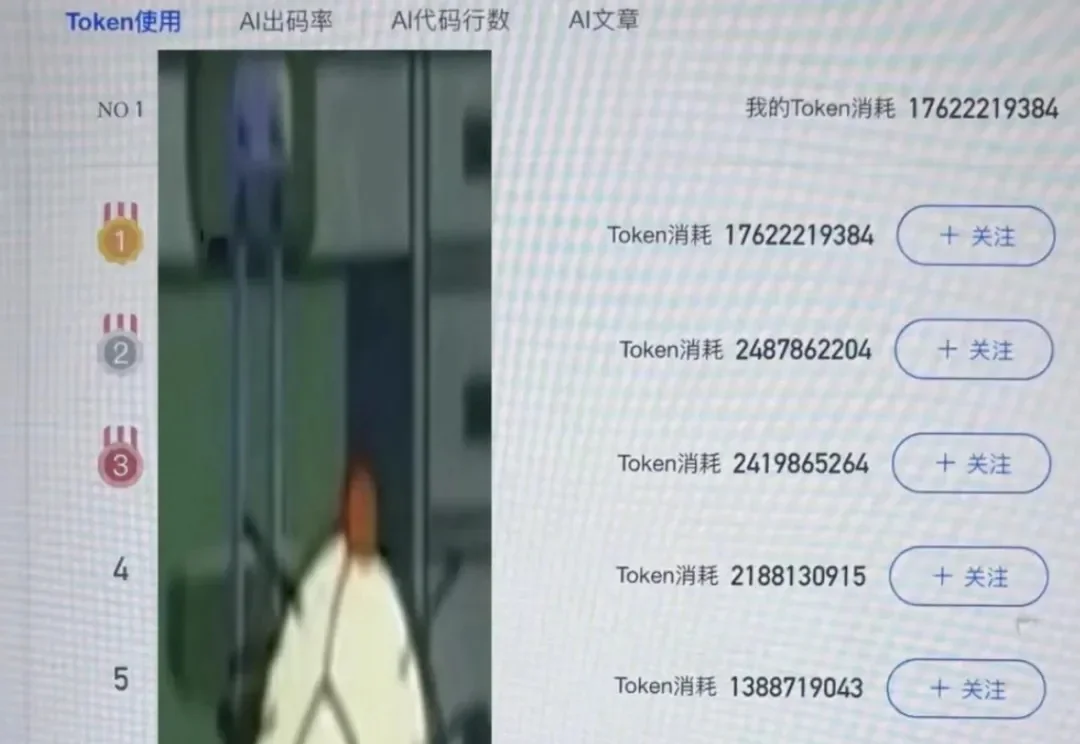
不用够token会被骂,AI生成率必须大于80%,谁在强制打工人用AI?

《读佳》获知,高德在内测一款Vibe Coding产品“袋马”(“代码”的谐音梗),主打自然语言驱动的零门槛应用构建能力,聚焦小程序与iOS原生应用场景,可快速生成可直接上线、真机可用的应用产品。截至目前,高德官方尚未对外披露该产品的正式上线时间、行业合作模式及商业化细则,相关产品动态仍处于内测阶段。

最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。
独家获悉,被称为“最像特斯拉”的具身智能公司智平方近日已完成新一轮融资,总额近50亿元人民币,估值突破200亿。据了解,本轮投资方阵容横跨国家队、大湾区产业资本、保险公司、头部券商及多家特斯拉供应链企业。公开数据显示,智平方此轮融资是迄今国内具身智能赛道单次披露金额最大的融资之一。