
Anthropic,被曝上市!
Anthropic,被曝上市!据外媒The Information援引知情人士消息透露, Anthropic的高管们已经讨论过最早于今年第四季度进行该公司的IPO(首次公开募股),可能在IPO中筹集超过600亿美元(约合4146.9亿元人民币)的资金。
来自主题: AI资讯
8147 点击 2026-03-27 14:57
 搜索
搜索
据外媒The Information援引知情人士消息透露, Anthropic的高管们已经讨论过最早于今年第四季度进行该公司的IPO(首次公开募股),可能在IPO中筹集超过600亿美元(约合4146.9亿元人民币)的资金。

就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。

Cursor套壳Kimi这事还没完…… 最新消息,Cursor放出Composer 2技术报告,力证自己还是有在“自研”。(doge) 不是纯套,而是有技术地套、循序渐进地套。用的方法,还是他们一开始就强调的预训练+强化学习。
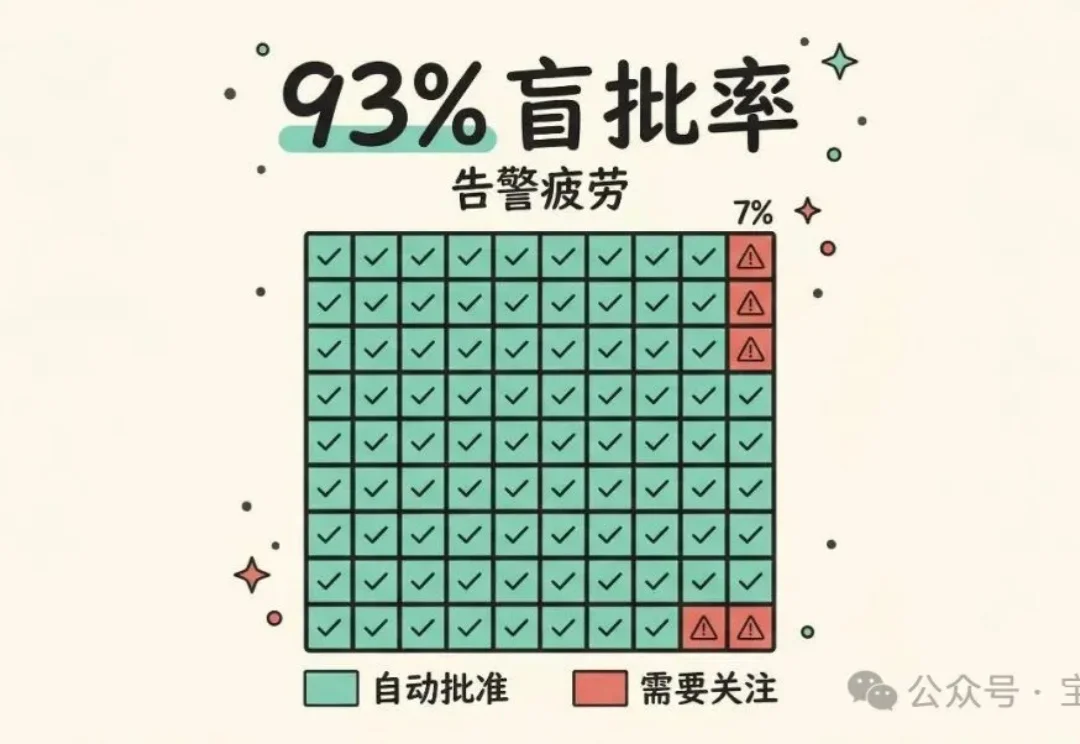
用 Claude Code 写代码的人都熟悉一个场景:Claude 每执行一个命令、每改一个文件,都要你点一次“同意”。Anthropic 的数据显示,用户 93% 的操作都会批准。也就是说,这个“安全审批”环节,绝大多数时候只是一个条件反射。

凌晨三点,Claude Code 迎来了一个大动作,堪称里程碑式的深水炸弹!

3月24日,Anthropic宣布Claude引入“Computer Use”能力,在Claude Cowork和Claude Code中,Claude可以直接操作用户的Mac电脑:打开文件、使用浏览器、运行开发工具,无需任何配置。该功能以研究预览版形式向Pro和Max订阅用户开放。
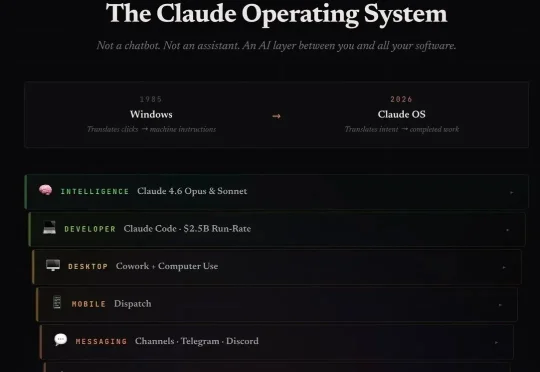
Anthropic的野心曝光了!有人分析称:他们在悄然打造一个AI操作系统,意图统治全球数字生态,做一个统治一切生态的龙虾大脑!这背后,剑指的就是苹果微软的6.4万亿帝国,而OpenAI甚至还排不上号。

Anthropic 今天同时发布了 Computer Use(电脑控制)、/schedule(云端定时任务)、还有 Claude Code Desktop。
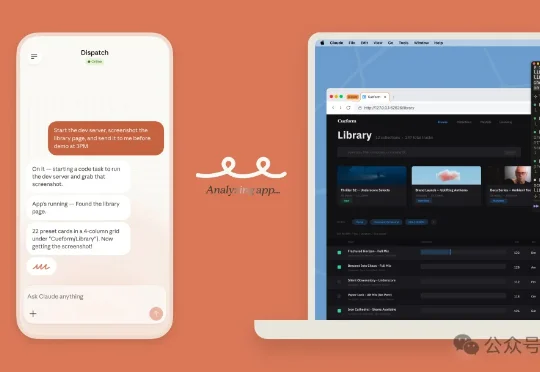
硅谷又炸了!今天,Claude全面接管人类电脑,绝杀OpenClaw,只需一部手机让AI 7x24h打工。就在刚刚,Claude彻底「虾化」了,正式获批全自主接管全球打工人的电脑。
2026年开年以来,Harness工程一词热度渐高,OpenAI在2月发布的一篇详细的内部实验报告标题中使用了此词,ThoughtWorks 首席科学家 Martin Fowler 在 X上也表示Harness工程是AI赋能软件开发的关键部分。