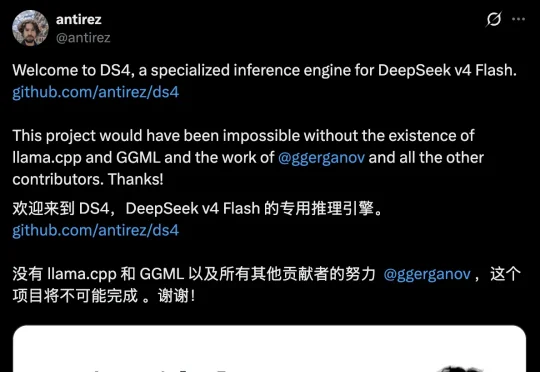
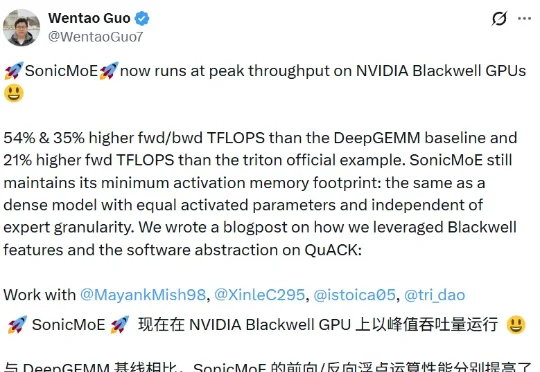
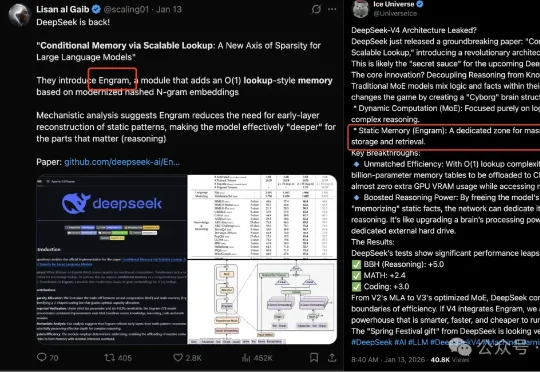
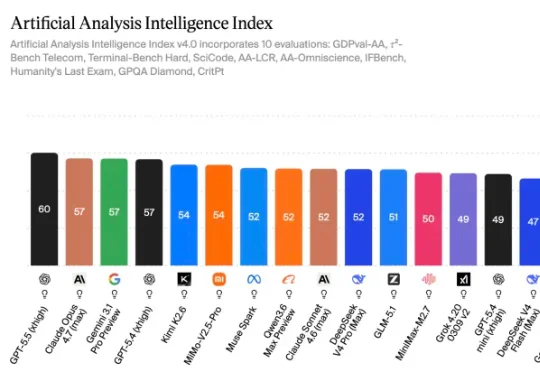
独家|3000亿估值博弈,DeepSeek和阿里巴巴谈崩了
独家|3000亿估值博弈,DeepSeek和阿里巴巴谈崩了4月,DeepSeek(深度求索)罕见展开一场巨额融资计划,同时吸引了腾讯和阿里巴巴两家大厂。我们独家获悉,近期,阿里巴巴和DeepSeek谈崩了。一位接近DeepSeek的人士告诉我们,双方未能在融资具体条款上达成一致。一方面,阿里的自有生态对DeepSeek而言,适配度不高,而DeepSeek也不缺乏外部注资的候选股东,希望尽量减少条款层面的束缚。
来自主题: AI资讯
10052 点击 2026-05-08 21:11