Sebastian Raschka长文:DeepSeek-R1、o3背后,RL推理训练正悄悄突破上限
Sebastian Raschka长文:DeepSeek-R1、o3背后,RL推理训练正悄悄突破上限只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。
来自主题: AI技术研报
9337 点击 2025-04-22 16:58
 搜索
搜索
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。
新国产AI视频生成模型横空出世,一夜间全网刷屏。Magi-1,首个实现顶级画质输出的自回归视频生成模型,模型权重、代码100%开源。整整61页的技术报告中还详细介绍了创新的注意力改进和推理基础设施设计,给人一种视频版DeepSeek的感觉。

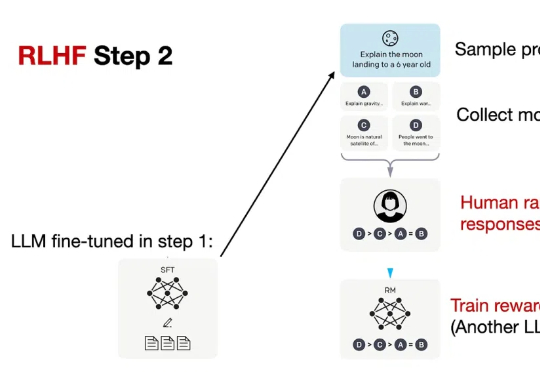
DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
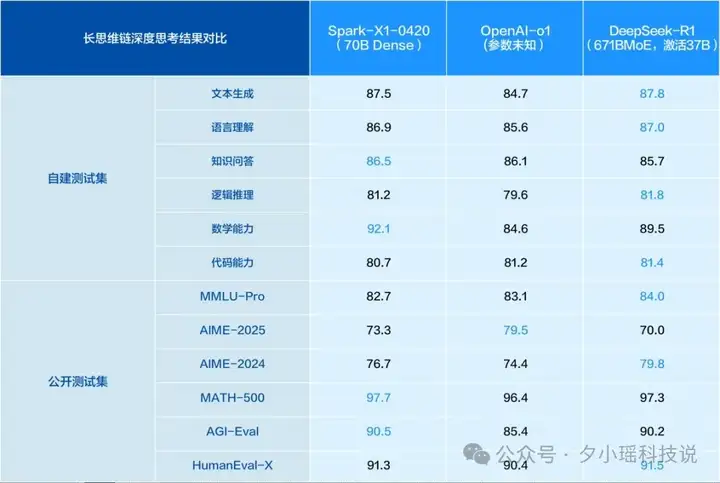
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。

Hyper-RAG利用超图同时捕捉原始数据中的低阶和高阶关联信息,最大限度地减少知识结构化带来的信息丢失,从而减少大型语言模型(LLM)的幻觉。

鲜为人知的是,目前国内超过60%的AI应用,包括DeepSeek的C端应用,联网搜索能力是通过集成博查AI的Search API实现的。大模型需要通过这类API,才能够动态获取最新信息,并输出给用户。AI搜索和传统搜索在入口端的界面上非常相似,底层技术和最终返回给用户的体验却截然不同。
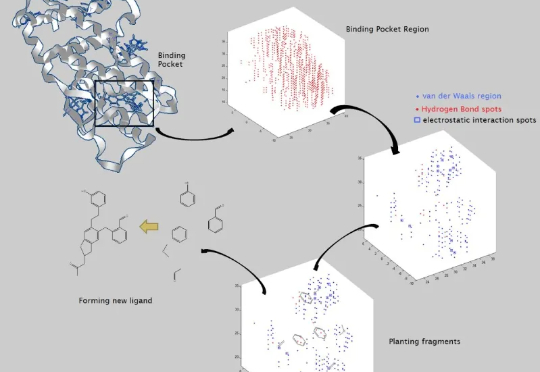
当前,人们对人工智能驱动的药物发现公司(以下简称 AIDD)这一新兴公司确发有效的界定。2025年开年,DeepSeek的爆火为AI医疗和AI制药领域带来了多维度变革。近日,BioPharma Trend发表了一份AI制药研究报告,报告力图从各个维度回答AI对生物医药的关键价值。

英伟达需要DeepSeek的“魔法”

推理模型与普通大语言模型有何本质不同?它们为何会「胡言乱语」甚至「故意撒谎」?Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。