ICLR 2026 | Shop-R1: 给AI补上「内心戏」,在RL博弈中复刻人类网购脑
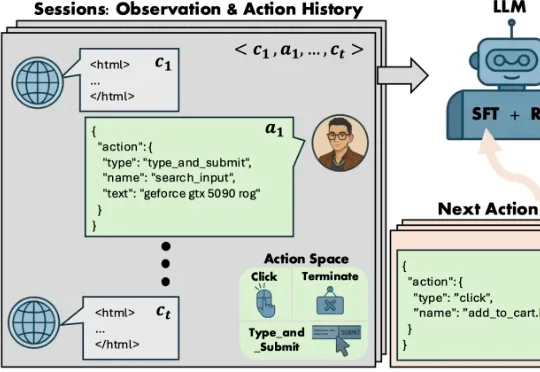
ICLR 2026 | Shop-R1: 给AI补上「内心戏」,在RL博弈中复刻人类网购脑传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。
来自主题: AI技术研报
7808 点击 2026-03-21 09:28