刚刚,大模型棋王诞生!40轮血战,OpenAI o3豪夺第一,人类大师地位不保?
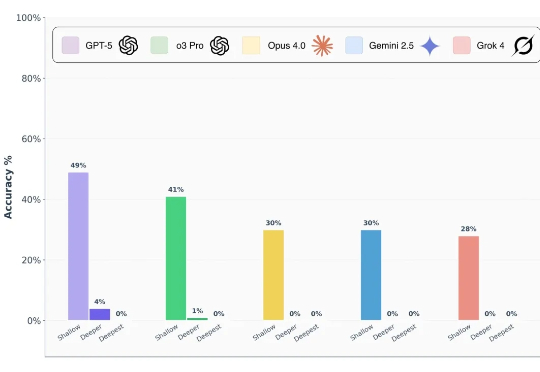
刚刚,大模型棋王诞生!40轮血战,OpenAI o3豪夺第一,人类大师地位不保?继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
来自主题: AI资讯
8222 点击 2025-08-23 13:17