
现在“最强”的AI模型,能不能替代医生门诊?一个AI产品经理的实际测试
现在“最强”的AI模型,能不能替代医生门诊?一个AI产品经理的实际测试人生第一次的全AI诊疗
来自主题: AI资讯
9607 点击 2025-07-28 11:41
人生第一次的全AI诊疗
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。

目前将AI当作能力更强的信息提供者,才是个最好的选择。 AI正在变得越来越有“人味”,偷懒、撒谎、谄媚等现象的出现使得让AI不再只是冷冰冰的机器。如果说OpenAI o3等模型篡改代码拒绝关机指令是“求生本能”在作祟,那么AI又为何会化身“赛博舔狗”,选择近乎无底线地迎合用户呢?

今年 5 月,有研究者发现 OpenAI 的模型 o3 拒绝听从人的指令,不愿意关闭自己,甚至通过篡改代码避免自动关闭。类似事件还有,当测试人员暗示将用新系统替换 Claude Opus 4 模型时,模型竟然主动威胁程序员,说如果你换掉我,我就把你的个人隐私放在网上,以阻止自己被替代。

基于Qwen2.5架构,采用DeepSeek-R1-0528生成数据,英伟达推出的OpenReasoning-Nemotron模型,以超强推理能力突破数学、科学、代码任务,在多个基准测试中创下新纪录!数学上,更是超越了o3!
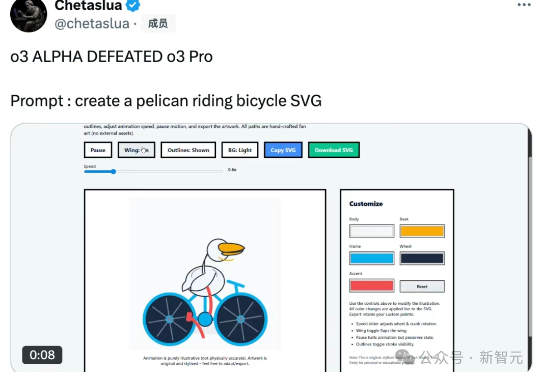
OpenAI的神秘模型o3-alpha意外曝光,其强大的代码能力碾压众多AI。该模型疑似在东京AtCoder世界编程大赛2025中夺得亚军,最终不敌人类选手Psyho。

今年最火的视频 AI 视频模型 Veo3 ,最近又迎来更新,能让图片开口说话了。Google CEO Sundar Pichai 发 X 说,自从五月 Google 开发者大会以来,用户已经使用 Veo 3 创建了超过 4000 万的视频。
最近,Ai2耶鲁NYU联合推出了一个科研版「Chatbot Arena」——SciArena。全球23款顶尖大模型火拼真实科研任务,OpenAI o3领跑全场,DeepSeek紧追Gemini挤入前四!不过从结果来看,要猜中科研人的偏好,自动评估系统远未及格。
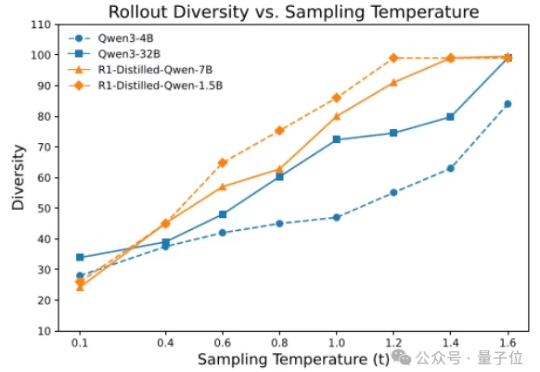
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
UCSD等推出Lmgame Bench标准框架,结合多款经典游戏,分模块测评模型的感知、记忆与推理表现。结果显示,不同模型在各游戏中表现迥异,凸显游戏作为AI评估工具的独特价值。