
云知声黄伟:从 token 价值到智能密度,热身赛结束后的 AI 游戏新规则
云知声黄伟:从 token 价值到智能密度,热身赛结束后的 AI 游戏新规则新一轮 AI 比赛才刚刚开始,而 token 生成数量不能作为唯一的指标。
来自主题: AI资讯
7533 点击 2026-05-18 16:49
 搜索
搜索
新一轮 AI 比赛才刚刚开始,而 token 生成数量不能作为唯一的指标。

太有意思了,刚看到河南郑州西亚斯学院的消息。有几位 00 后创业者回母校干了件事,给学校捐了 20 亿 Token,希望带动学弟学妹做一人公司创业。郑州西亚斯学院是泡泡玛特老板王宁的母校,看来这学校真挺能出人才的。
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

英国AI安全研究所(AISI)昨天扔下重磅炸弹:Mythos在模拟企业内网32步渗透任务中10次过6,GPT-5.5也跟着10次过3,连此前所有模型都没破过的Cooling Tower靶场都被首次攻破!更炸的是——Cyber能力翻倍周期一路压到4.5个月,瓶颈不是智力,是Token。这场ASI决赛,人类评测已经追不上AI了。
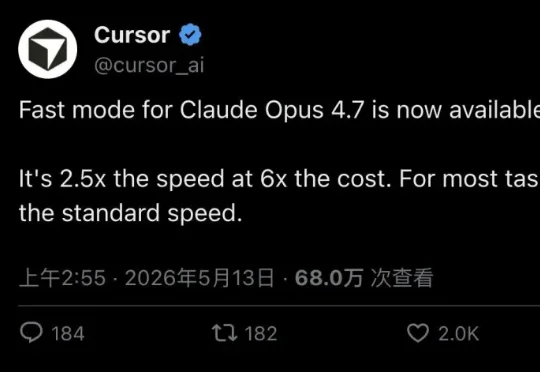
Cursor 正式接入 Claude Opus 4.7 Fast mode——同一个旗舰模型,拆出两个速度档。快 2.5 倍,贵 6 倍,输出价每百万 token 150 美元。最离谱的是,Cursor 官方在发布当天就建议:多数任务请用标准速度。

AI工具最残酷的检验场,不在硅谷,而在义乌。
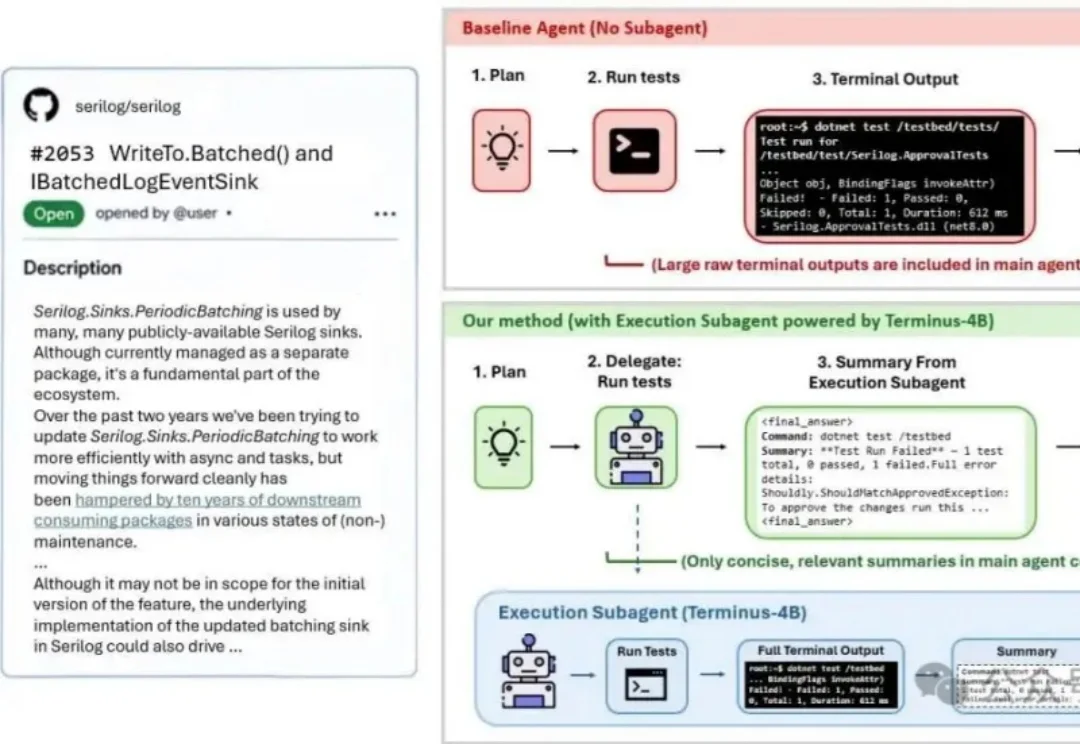
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

上次 WinClaw 的超级 VIP 计划推出 10000 个免 token 名额时我就想发,可惜我看到的时候名额已经被抢空。今天突然刷到活动又返场了!5 月 7 日到 5 月 17 日,又有 8000 个 Token 永久免费名额可以申请
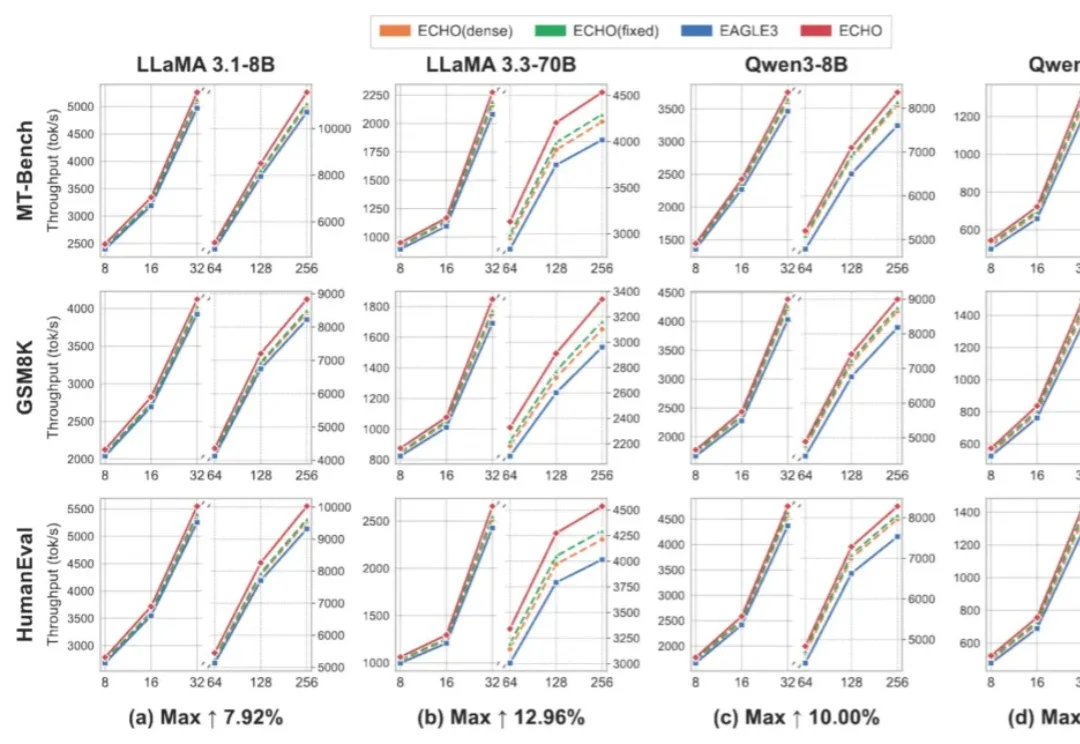
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。