
百万Token白烧?Claude官方下场:5招治好上下文腐烂
百万Token白烧?Claude官方下场:5招治好上下文腐烂给了100万token,现在却手把手教你怎么删记录!Anthropic官方承认:塞太多东西,Claude就会变蠢。面对失控的「上下文腐烂」,Anthropic连夜甩出5招救命指南。
来自主题: AI技术研报
10037 点击 2026-04-19 13:35
 搜索
搜索
给了100万token,现在却手把手教你怎么删记录!Anthropic官方承认:塞太多东西,Claude就会变蠢。面对失控的「上下文腐烂」,Anthropic连夜甩出5招救命指南。

跑分最高未必能赢,但最懂Harness的可以。如今,被Hermes、OpenClaw等全球爆火开源Agent项目「钦定」为默认的MiniMax,在OpenRouter上的日均Token消耗已飙到3000亿。
浪费的原因很具体,AI应用从“对话”转向“执行”,这些计算资源流向了较贵的大型旗舰模型,Agent在复杂多轮任务中,历史文件、对话会不断累积,大量无用、冗余、过期的信息会不断产生并且重复计算,Token消耗因此指数级增长。也就是说,企业和开发者在用最贵的车跑最短的路。
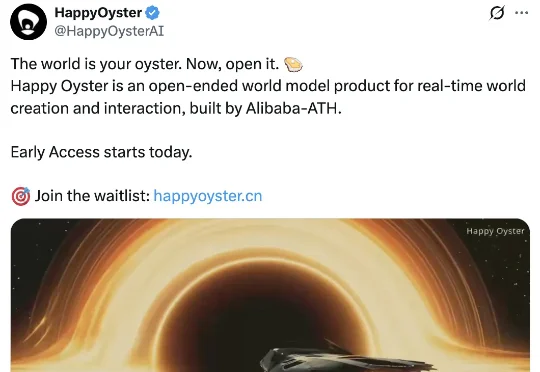
就在刚刚,成立恰满一个月的阿里ATH(Alibaba Token Hub)事业群,发布全球首个主动式实时交互的世界模型产品。名也挺有趣的,叫HappyOyster(快乐生蚝)。HappyOyster搭载原生多模态架构,背后是支持多模态输入与音视频联合生成的流式生成世界模型,核心主打漫游(Wander)、导演(Direct)、创造(Create)、分享(Share)。
养虾已经成为我们团队的日常了,几乎人手都有一只🦞要养,不仅能实时抓取全网前沿 AI 资讯速递,还能干一些搬砖杂活。

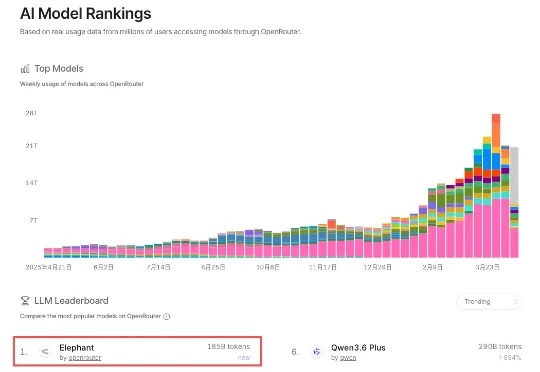
这两天,一款名为Elephant(大象)的匿名模型,在OpenRouter上悄然亮相。上线不到48小时,这一模型已经冲到OpenRouter热榜(Trending)第一,目前调用量超过1850亿个token。

凌晨,英伟达CEO黄仁勋接受了知名科技主持人Dwarkesh Patel的专访,长达1小时45分钟。

我们发布了TokenDance 词元跳动,一站式大模型 API 调用平台。希望能够赋能更多观猹生态内的 AI 企业、OPC 开发者与 AI 爱好者,帮助 AI 时代的创造者们,省一些成本,多一些创造。

已经记不清这是第几次,有网友爆出来 Claude 降智了,思考深度下降 67%,Opus 幻觉加深。关键是能力变弱和可靠性降低的同时,我们的 Token 使用还增加了。 网友们在社交媒体上抱怨,「过去

2025年之前,想要证明自己混得好,大概得腕上戴块百达翡丽,车库里停辆库里南。但到了AI时代,硬通货变了:看你一年到底烧了多少Token。一年烧掉250亿个Token,有位25岁的韩国小伙子,成了全世界最能烧的人。