
腾讯投的上海AI芯片独角兽,要IPO了!拟募资60亿
腾讯投的上海AI芯片独角兽,要IPO了!拟募资60亿腾讯持股20%,年销3.9万张AI加速卡及模组。
来自主题: AI资讯
8088 点击 2026-01-23 11:23
 搜索
搜索
腾讯持股20%,年销3.9万张AI加速卡及模组。

近日,北京浩瀚深度信息技术股份有限公司(以下简称“浩瀚深度”)与云边云科技(上海)有限公司(以下简称“云边云”)的股东签署了《股权/财产份额收购协议》,浩瀚深度及其子公司合肥浩瀚拟以8575万元收购云边云公司35%的股权。
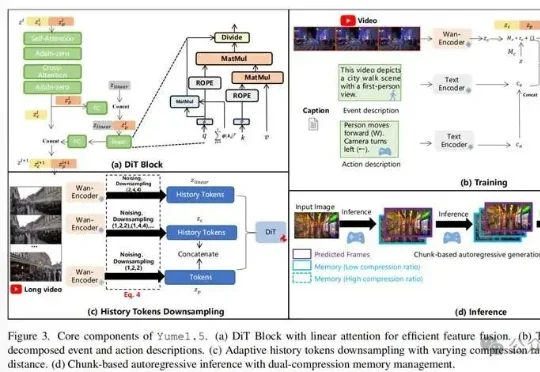
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。
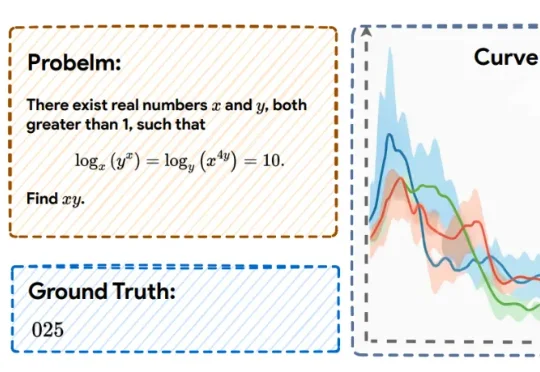
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:
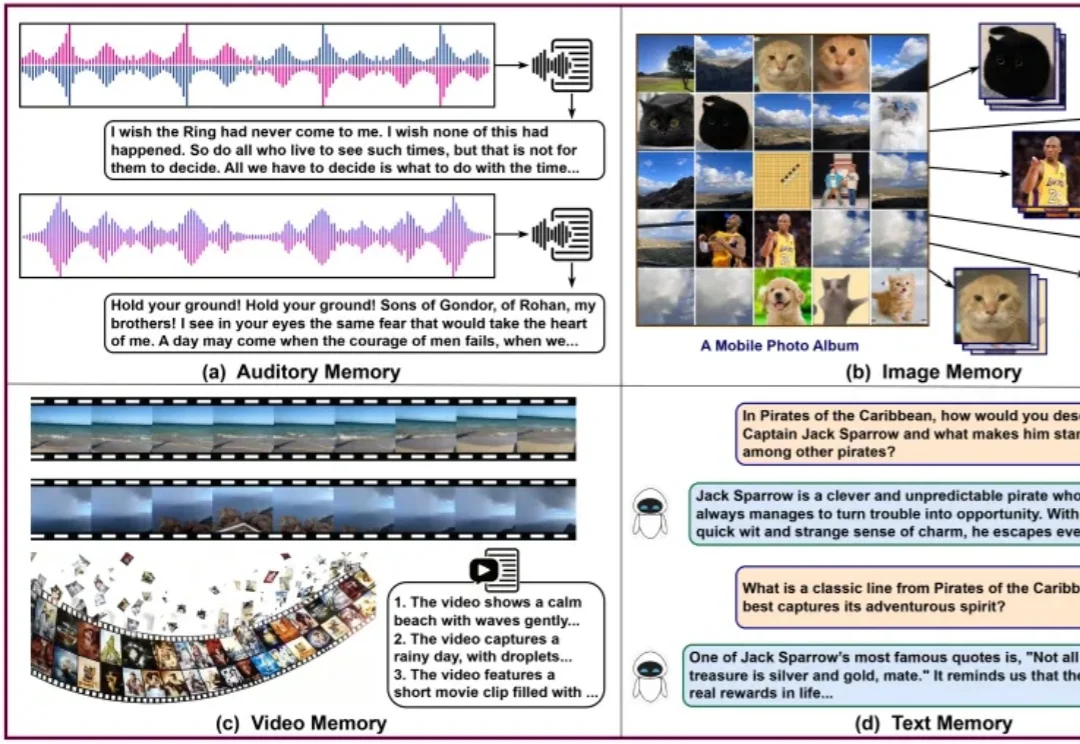
一页纯文本的记忆是看不清世界的。

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。

上海前三季度GDP增5.5%,AI制造业增12.8%,成增长引擎。
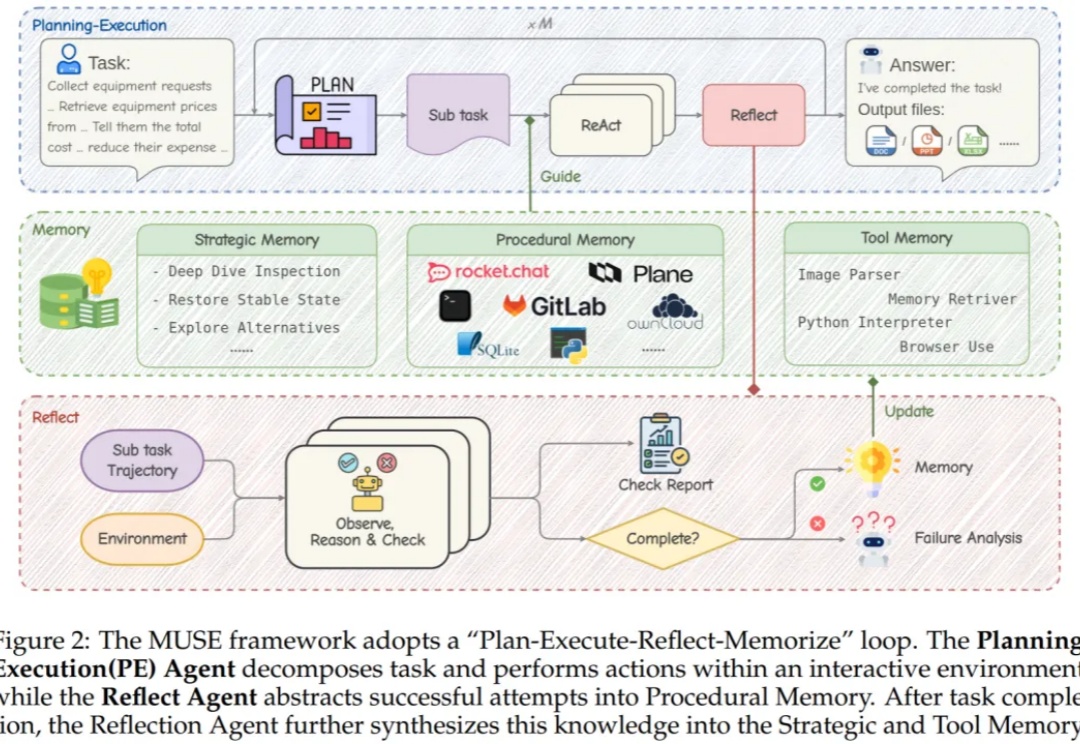
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?
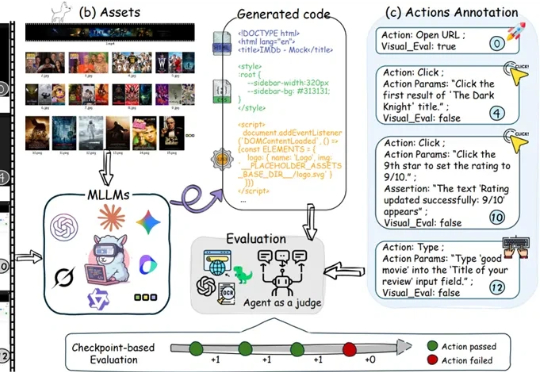
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
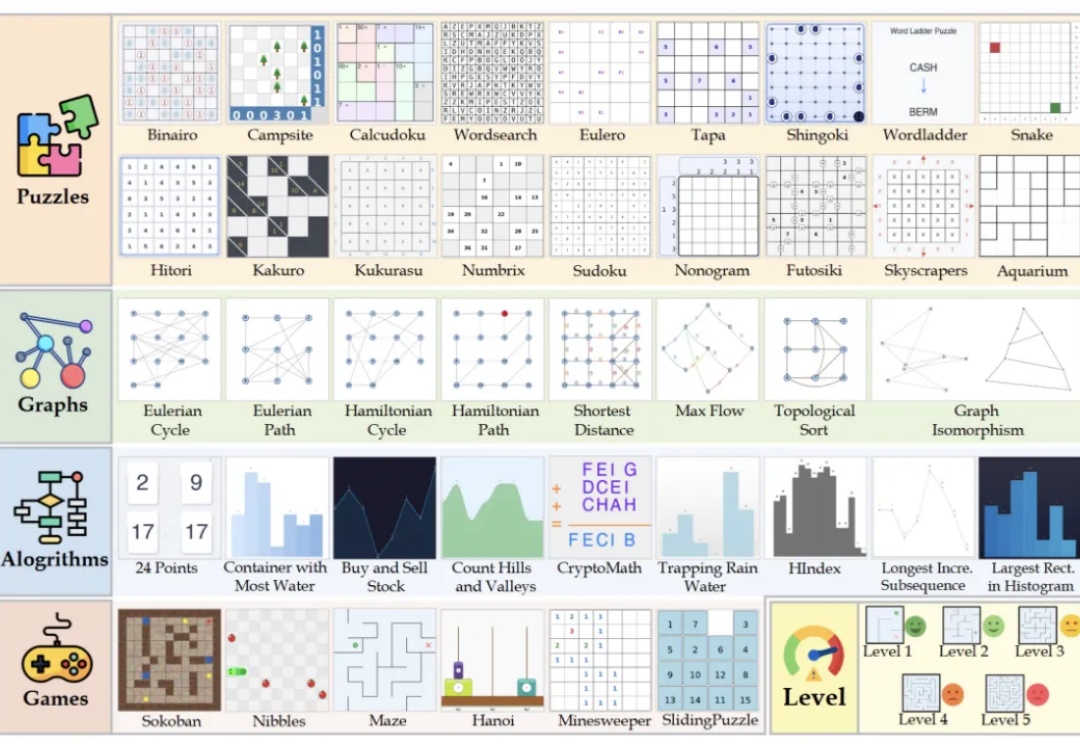
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。