
AI也会「看人下菜」?Anthropic勾勒出了Claude的价值观画像
AI也会「看人下菜」?Anthropic勾勒出了Claude的价值观画像同一个问题,换一种语言问 Claude,得到的可能不只是措辞不同的答案。
来自主题: AI资讯
7611 点击 2026-07-14 15:52
 搜索
搜索
同一个问题,换一种语言问 Claude,得到的可能不只是措辞不同的答案。

不知不觉,整个AI影像行业全线迈进了Agent创作与AI视频C端普及的时代。

3D空间数据的瓶颈,从来不是算法,而是标注。

Reve 在 7 月 9 日把图像模型迭代到了 2.1 版。距离 2.0 发布刚好一个月,放在基础模型圈子这不算常见。前面只挡着一个 OpenAI 的 GPT Image 2。另外官方说:「训练这版模型用的算力不到排行榜前后邻居的十分之一」。

又一家超级百亿独角兽,打出冲刺上市的明确信号。

Anthropic刚刚放出了一段内部对谈,主角是三位负责Claude Platform的高管,三人聊了聊过去半年里,智能体基础设施到底发生了什么变化,包括身份、权限、记忆、智能体之间怎么互相通信,企业该怎么算智能体的投资回报率,

都以为AI应该先去替数学家证定理,陶哲轩却让它搬30年前的旧网页。一天迁走560篇论文,还从他二十多年前亲手写的老代码里揪出两个连他都不知道的bug。

7 月 8 日,xAI 发布了 Grok 4.5。马斯克给的定位很直白,「Opus 级别,但更快,更便宜」。
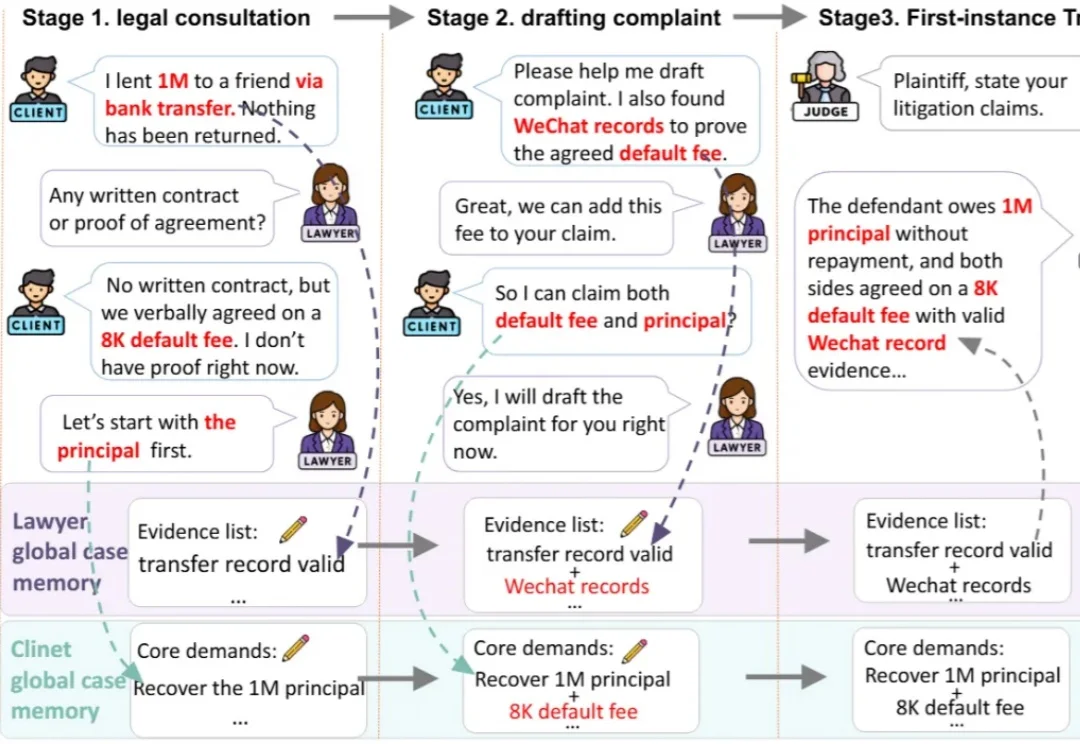
打官司,从来不是一问一答就能结束的事。

4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。