
YC点名创业方向:AI欺诈猎手,可能干掉整个反欺诈行业!
YC点名创业方向:AI欺诈猎手,可能干掉整个反欺诈行业!刚刚,YC最新创业清单点名「AI欺诈猎手」。当黑灰产开始用AI作案,防守方也在组建智能体军团——反欺诈的终局,或许不是更强风控,而是一个自带安全基因的智能体世界。
来自主题: AI资讯
10629 点击 2026-03-05 14:22
 搜索
搜索
刚刚,YC最新创业清单点名「AI欺诈猎手」。当黑灰产开始用AI作案,防守方也在组建智能体军团——反欺诈的终局,或许不是更强风控,而是一个自带安全基因的智能体世界。
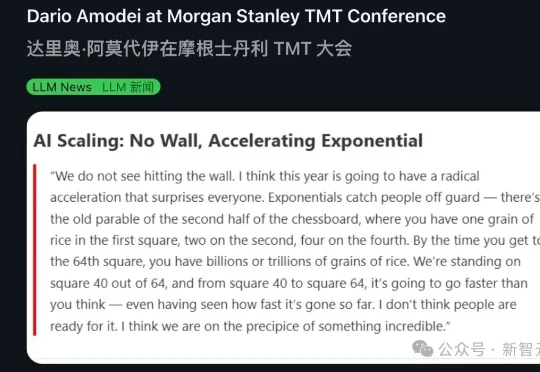
Anthropic CEO Dario Amodei在摩根士丹利会议上扔出一颗深水炸弹:Scaling Law根本没撞墙,2026年将迎来激进加速。他用棋盘稻米寓言做了个精准比喻——我们正站在第40格,前39格的所有震撼加在一起,不过是后24格的零头。这场指数级狂飙,没人准备好。

陶哲轩办公室有 6 块黑板,他说绝不放弃。但他刚带 50 个人用 AI 和代码解决了 2200 万道数学题。

Openclaw是不是不如骆老师轶航家的狗还需要探讨,但云端Openclaw肯定是路边一条。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。

亏贼! GitHub热榜,居然被纸片人占领了—— 不是手办,是AI。你的赛博老婆,开源了。
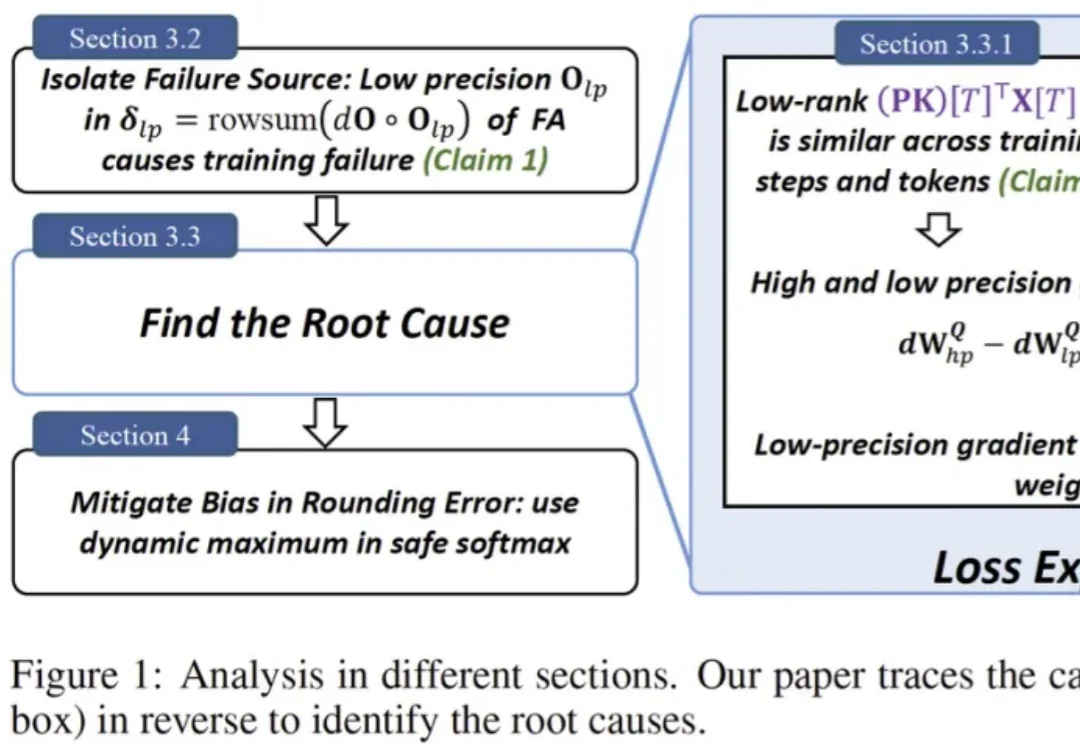
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
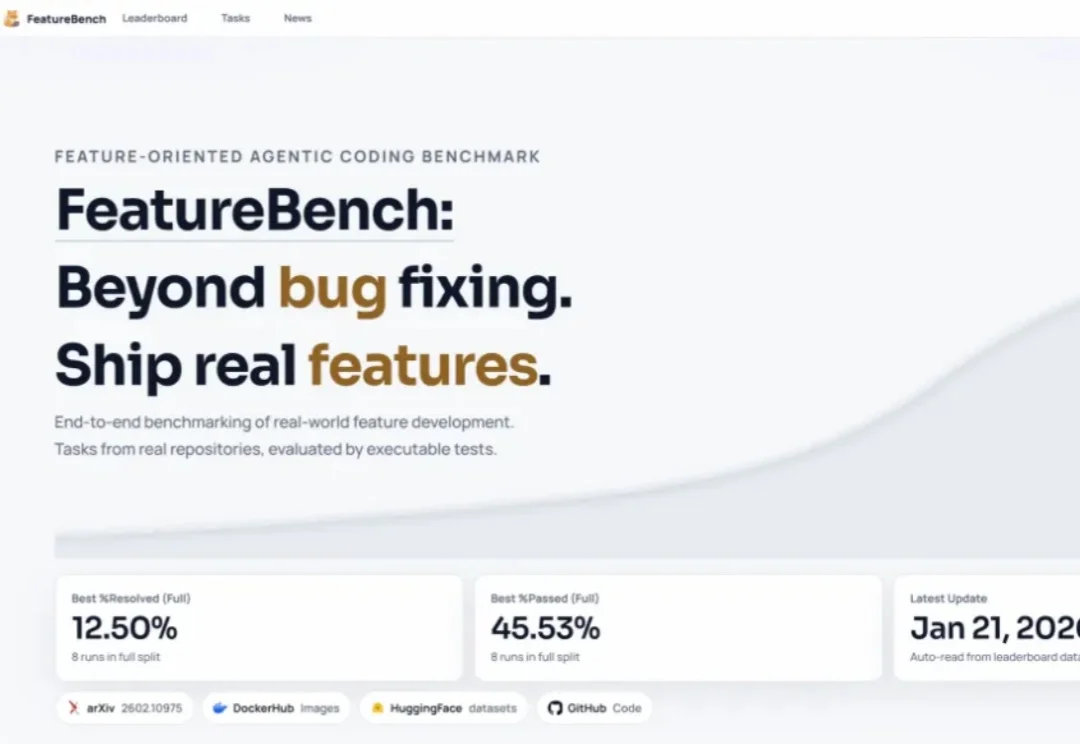
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

最近关于OpenClaw的事,除了我昨天说的Github登顶之外。还有另一个非常魔幻的事——就是OpenClaw收费上门安装。一次费用,几百不等。更离谱的价格也有,前段时间在群里看到的:OpenClaw安装,1.6万!?

GPT-5.3 Instant不卷跑分,专治「聊天翻车」:不再动不动拒绝回答,不再满嘴说教免责,幻觉率暴降27%,写作能力也跳了一个台阶。