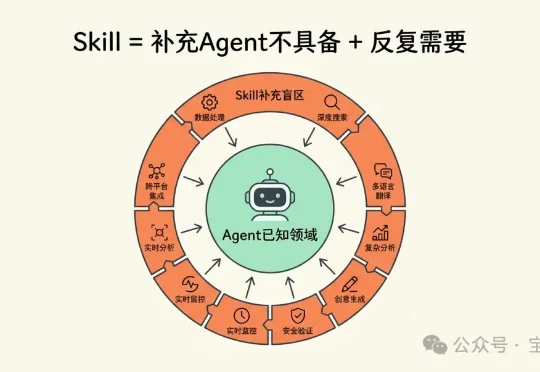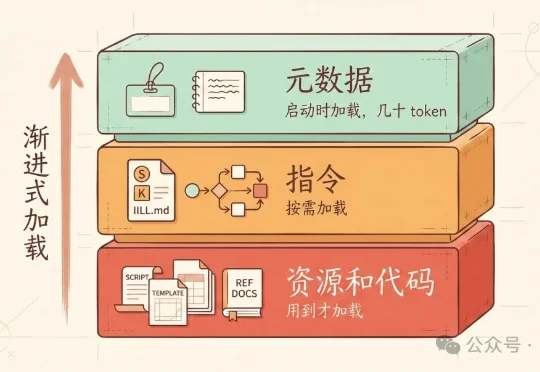
“Skill 不就是长一点的提示词吗?”
“Skill 不就是长一点的提示词吗?”上篇文章别把整个 GitHub 装进 Skills,Skills 的正确用法发出去后,收到一些质疑:“说 skill 能做配图 prompt 不行。本来 skill 就是加载 md,没 skill 之前我们用 prompt 模板照样也是能做流程编排。” “现在大部分 skill 不就是长一点的提示词吗?为什么说'单纯靠提示词做不了'?”
来自主题: AI技术研报
8385 点击 2026-01-25 11:59