
一口气集齐老黄苏妈英特尔,还得是AI,还得是联想
一口气集齐老黄苏妈英特尔,还得是AI,还得是联想联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
来自主题: AI资讯
9716 点击 2026-01-09 14:41
 搜索
搜索
联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
百炼升级了其提出的「1+2+N」的蓝图:其中最底层的 1 是模型与云服务,中间层的 2 是高代码、低代码的开发范式,在最上层的 N 则是面向不同任务的开发组件。这套能力覆盖了生产级智能体构建的全生命周期。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。

出走5年,估值翻倍!曾被嘲笑「太保守」的Anthropic,正凭3500亿美元身价硬刚OpenAI。看理想主义者如何靠极致安全与Coding神技,在ARR激增的复仇路上,终结Sam Altman的霸权!

在 2026 年的 CES 全球消费电子展上,AI 硬件无疑是不可忽视的一支—— 小至能根据指令作画的 AI 画框,大到能叠衣服的家务机器人......AI 已经无处不在。
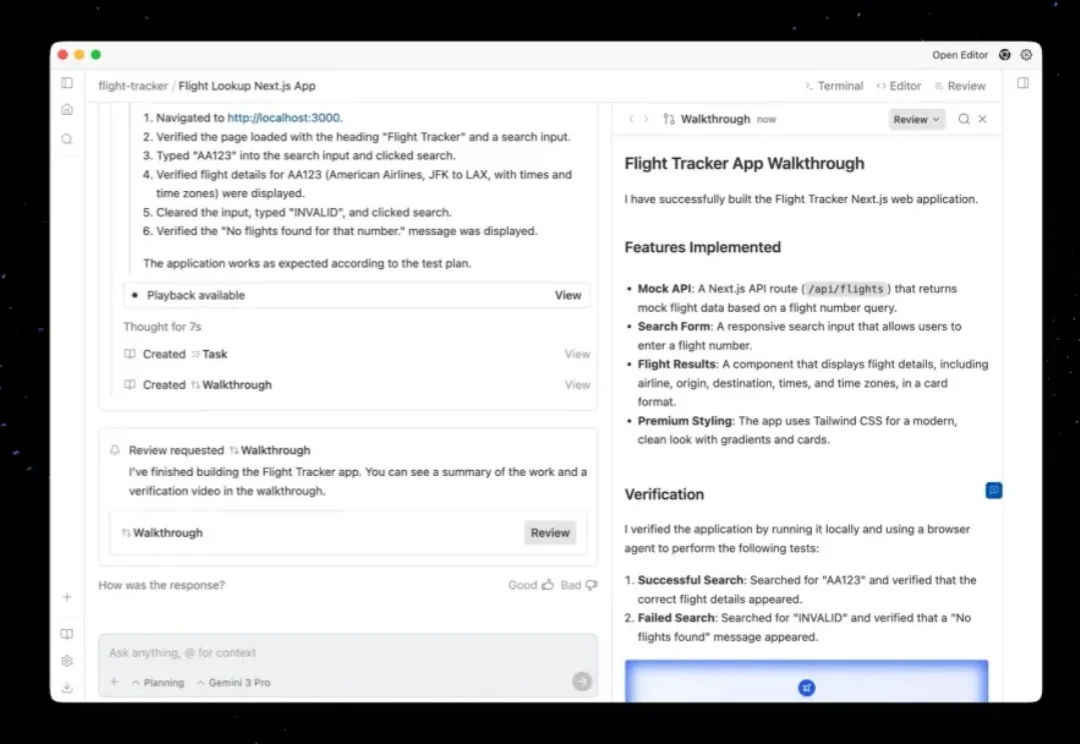
2026 年,基模会不会吃掉所有应用场景?

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

提起“AI战胜人类”,很多人第一反应是1997年IBM的“深蓝”击败国际象棋世界冠军卡斯帕罗夫。那场人机大战轰动全球,被视为人工智能的里程碑。

抛开产品体验不谈的话,Rokid无疑是国内AR眼镜的先行者,他们用眼镜这个不可能三角最难平衡的硬件形态,硬是推出了10几个功能,客观上也推进了全产业链的发展。

在上期内容发布后 有很多小伙伴都反馈很好用 NotebookLM改不了细节?提示词 V2.0 生成既有质感,又能随意修改文字的完美 PPT