
AI幻觉最可怕的人类副作用出现了
AI幻觉最可怕的人类副作用出现了最新研究发现,AI幻觉不只会骗你了,还能喂大你的自信心、削弱你的判断力。
来自主题: AI技术研报
6273 点击 2026-07-23 16:01
 搜索
搜索
最新研究发现,AI幻觉不只会骗你了,还能喂大你的自信心、削弱你的判断力。

在此之前,梁文锋曾提出“不融资、不上市、不商业化”的原则。此次大规模融资标志着DeepSeek正式走向资本市场,也引发了业界对其商业化路径与技术愿景的广泛关注。在近期的一场投资者交流会上,梁文锋详细阐述了DeepSeek的组织文化、开源逻辑、技术路线图以及对行业竞争格局的看法。

业界首个国产芯片上跑出的万亿参数模型LongCat-2.0于近日发布。
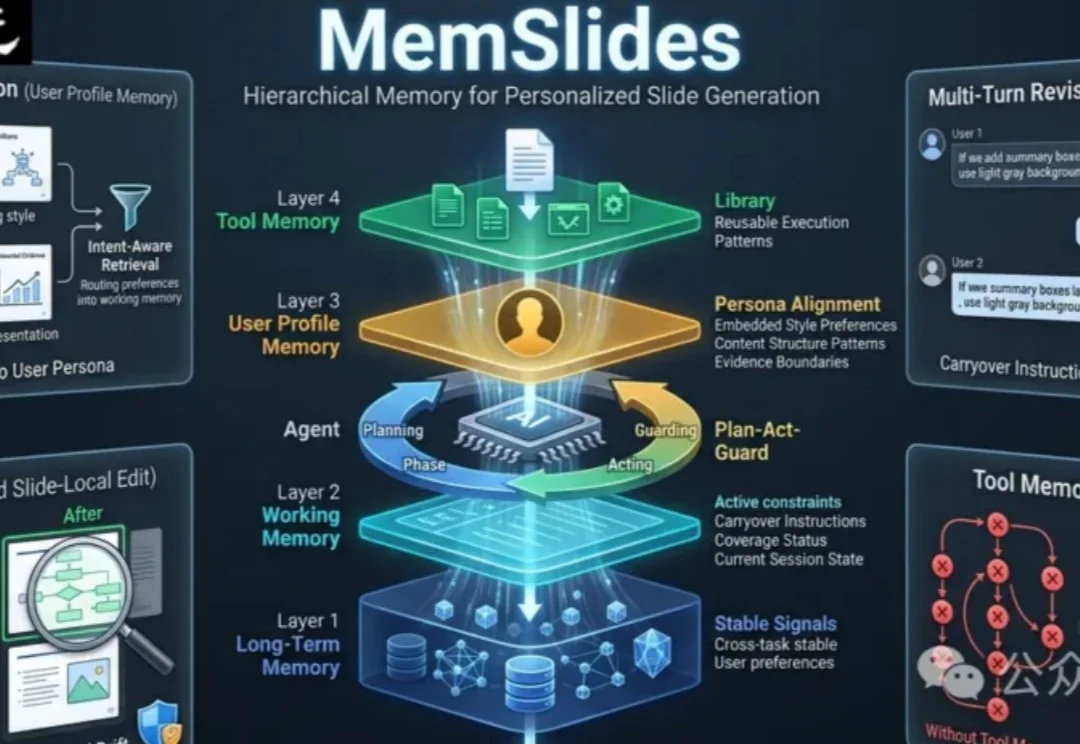
最尴尬的一刻,往往不是AI PPT生成失败。

昆仑万维把世界模型玩出了新花样。
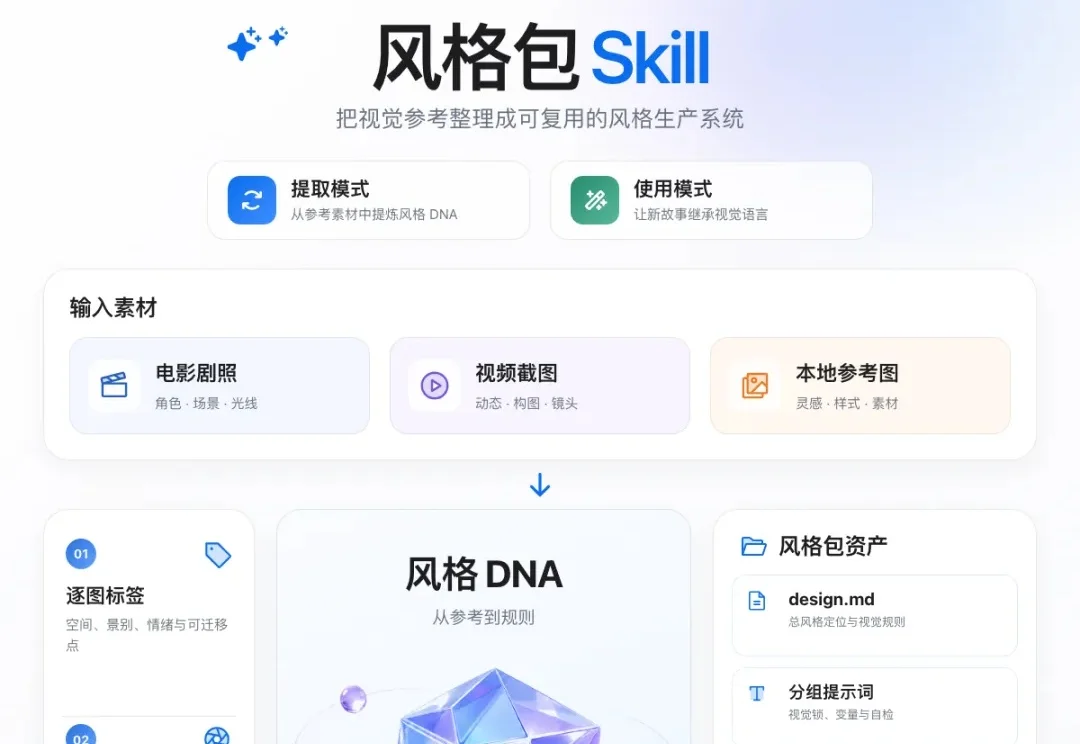
嗨大家好!我是阿真! 刷短视频就是这点不好,上次看到一个 AI 视频拆解分析的教程,感觉很有意思,刷完了过两天忘记在哪里刷的了。

刚刚,北京市发布了一份特别重磅的政策文件。《北京市关于加快智能体引领发展的若干措施》文件不长,一共10条。但我把它从头到尾看完以后,我的第一反应是,这份政策真的有点太新了。Agentic AI、Harness Engineering、AI OS、FDE、OPC、Token经济、TaaS、AaaS、RaaS、Token工厂、AIP。

2026 年 7 月 20 至 24 日,硬核少年技术节 5.0 在杭州、北京共同举办。
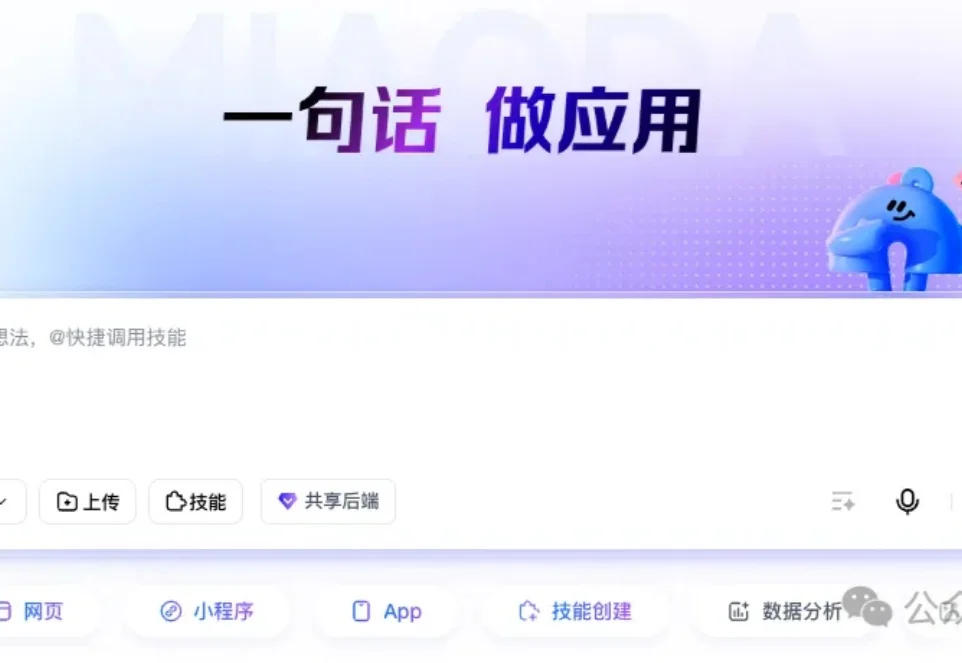
WAIC 2026上,百度秒哒带来了3.5版本。据官方数据,秒哒累计服务超过3500万用户,创造了350万个具有商业价值的应用,每天有近20万人在使用这些应用解决真实问题。

热热热热热!今年 WAIC 现场,大家对 AI 的热情,像上海的气温一样持续攀升。