
独家|DeepSeek 50亿起投,最新估值高达3000亿
独家|DeepSeek 50亿起投,最新估值高达3000亿一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。
来自主题: AI资讯
8565 点击 2026-04-23 17:09
 搜索
搜索
一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。
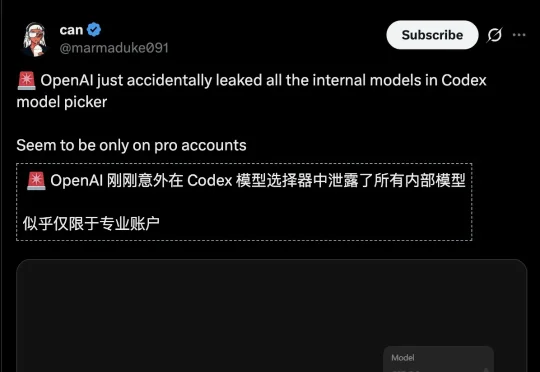
就在刚刚,Codex平台爆发重大泄漏事故,内部测试环境疑似误推生产环境。GPT-5.5、「风速狗」Arcanine、「海森堡」以及神秘的Glacier集体亮相。奥特曼口中那个「比Transformer更伟大的架构」,难道已经藏在这些模型背后?
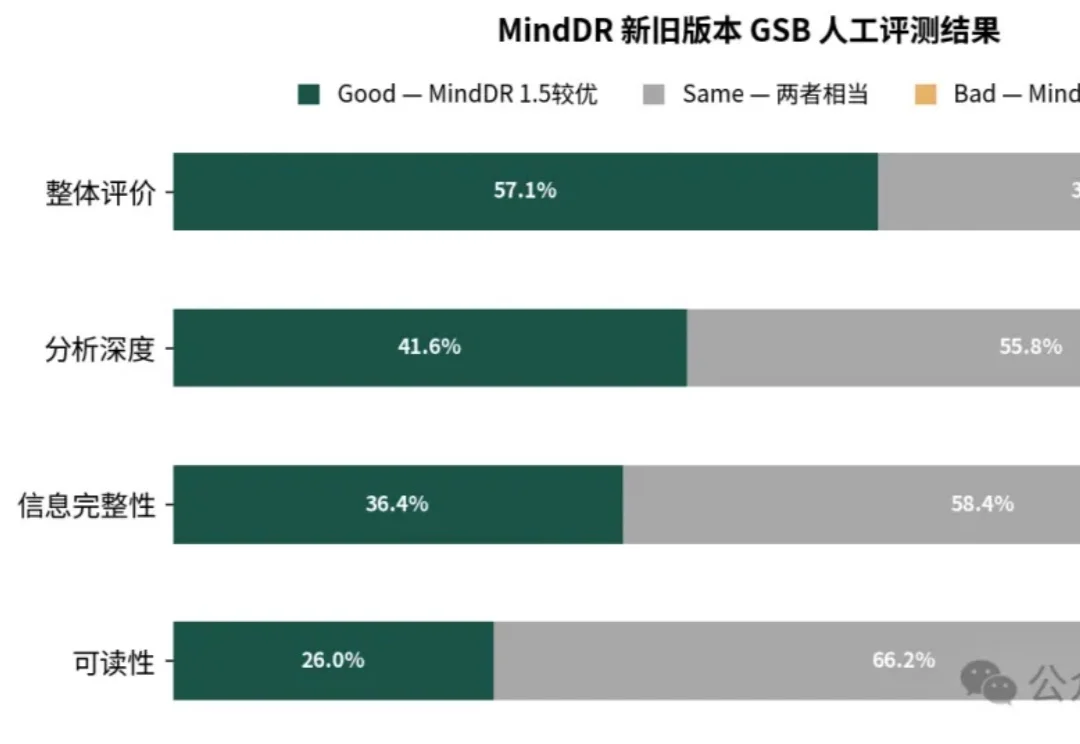
理想汽车信息智能体团队发布 MindDR 1.5,在 DeepResearch Bench 榜单中取得 52.54 分,以 30B 参数规模达到业界领先水平,性能优于同等规模的开源智能体系统。

本文深度拆解 AI 笔记应用Coconote的创业与收购全历程:创始人 Brett Bauman、Zack Hargett 于 2023 年 4 月推出产品,零广告预算,靠一系列反常规决策,仅用两年实现670 万美元 ARR,最终被教育科技巨头 Quizlet 收购。

投资者正在积极争取AI 研究人员创办初创公司,以使 AI 更加可靠和高效。

上周六,我们在上海举办了第一届通灵黑客松。
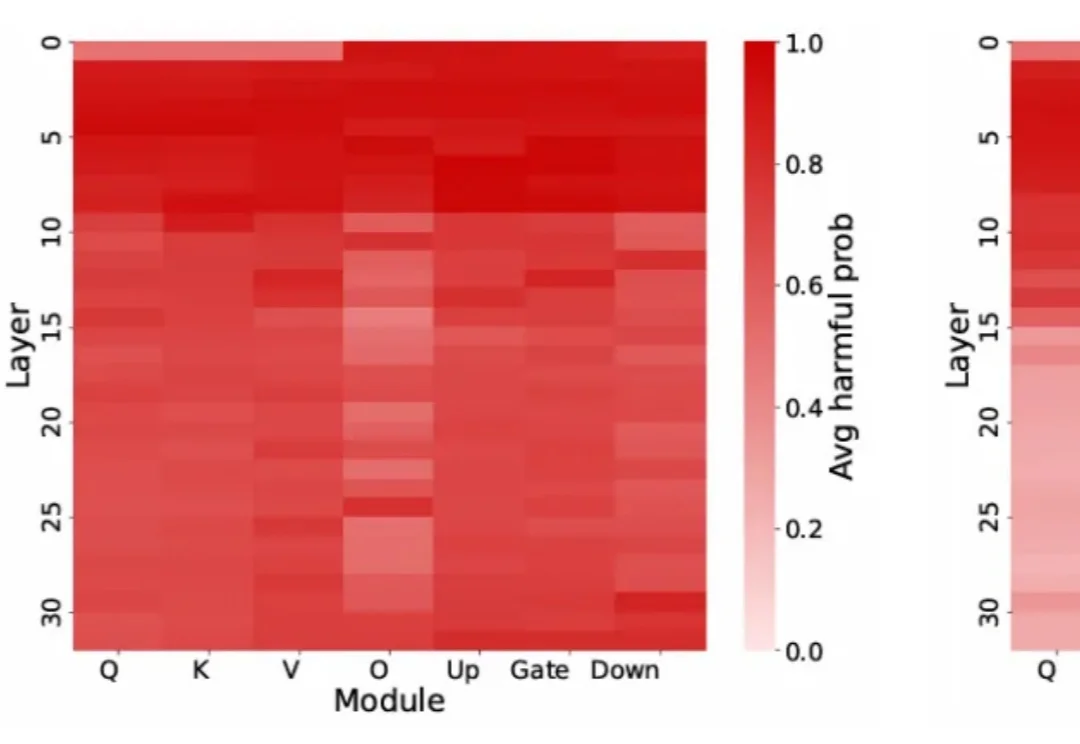
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!

2026年出海:靠“陪聊AI”活着的公司都在死去,这几家企业凭什么翻倍暴涨?

估值飙至200亿美元。