
林俊旸点赞!AI-First是年轻人的机会,最佳实践公开了
林俊旸点赞!AI-First是年轻人的机会,最佳实践公开了为什么你的“AI优先”战略可能大错特错?一文读懂。
来自主题: AI技术研报
8940 点击 2026-04-16 13:01
 搜索
搜索
为什么你的“AI优先”战略可能大错特错?一文读懂。

近日,国内多模态生成式人工智能公司智象未来(HiDream.ai)宣布完成超5亿元新一轮融资。本轮融资由东方富海、安徽省投资集团旗下的省产业投资公司、峰华资本等新股东联合投资,同时合肥产投、兴泰集团、合肥高投、安徽省人工智能母基金等老股东持续加注。

全球最强编程模型,中国造。

“先生,你也不想你婚外情被曝光吧?不想的话就照我说的做。”
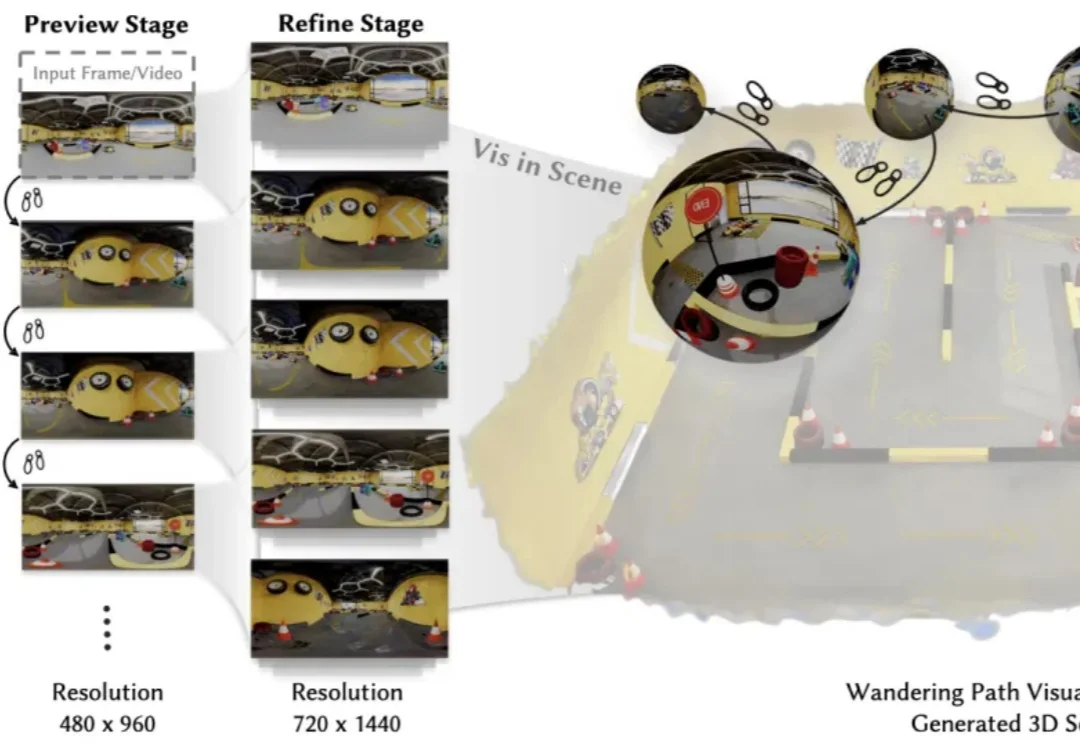
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:

当一家成立不到两年、团队规模不过 10 人的创业公司被收购,并在数周内关闭产品、清空数据,这通常不会成为行业关注的焦点。但这一次不同。收购方是 OpenAI,而被收购的,是一家试图用模型重写个人理财方式的初创公司——Hiro Finance。

Anthropic正式推出了Claude Code的自动化任务功能Routines,目前处于研究预览阶段。只要配置好一次提示词、代码仓库和连接器,Claude就能在云端全自动干活了。这些任务全部运行在Anthropic的云端基础设施上,意味着完全不需要你一直开着电脑,哪怕你下班关机,它也能按时帮你处理代码积压、审查代码,甚至随时响应云端事件。
上周,我们发布了 MMX-CLI,让 Agent 可以直接通过命令行调用 MiniMax 的全模态能力。命令行是 Agent 在终端中完成工作的常见形态,但用户的工作并不只发生在命令行内,电脑上还有大量任务藏在命令行无法触达的本地软件、内部系统和图形界面中。

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。

扎克伯格携手Broadcom签下五年长约,自研芯片、GW级数据中心、百亿美元挖人——Meta正式向「人手一个超级智能」的终极目标发起冲锋。