
Claude 4 核心成员:2027 年,AI 将自动化几乎所有白领工作 | 万字对谈
Claude 4 核心成员:2027 年,AI 将自动化几乎所有白领工作 | 万字对谈AI coding 这条 AI 行业今年的主线,在最近这段时间愈发清晰。
来自主题: AI资讯
8370 点击 2025-05-31 17:15
 搜索
搜索
AI coding 这条 AI 行业今年的主线,在最近这段时间愈发清晰。

据 BloomBerg 报道,Abridge AI Inc. 是一家利用人工智能转录医疗对话的AI笔记初创公司,目前正在进行一轮由 Andreessen Horowitz 领投的 3 亿美元新融资。
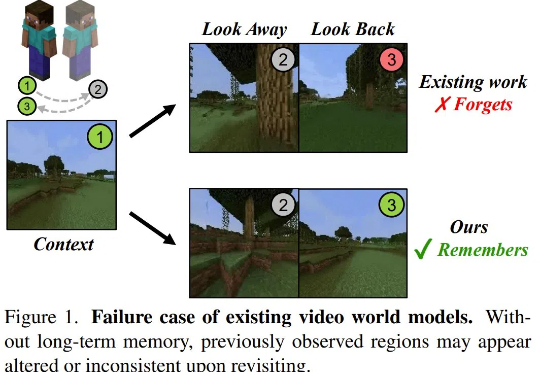
当状态空间模型遇上扩散模型,对世界模型意味着什么?

2025年,DeepSeek迅速席卷全国医疗行业。
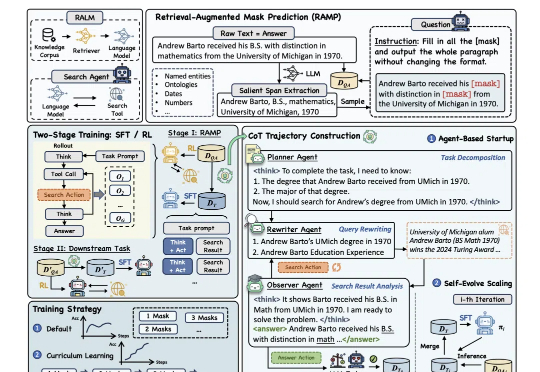
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
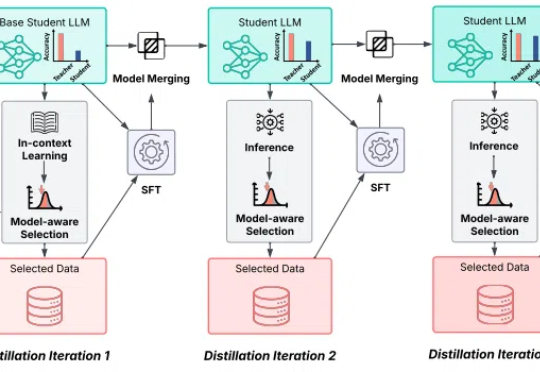
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。

人工智能搜索引擎Perplexity重磅发布新产品Perplexity Labs,这是一款面向专业版用户(20美金/月)的智能Agent工具,为用户提供了更强大的生产力解决方案。用户可以在搜索框下方一键切换至"实验室模式",通过该模式可高效生成:专业分析报告、结构化电子表格、交互式网页应用、数据可视化图表等。
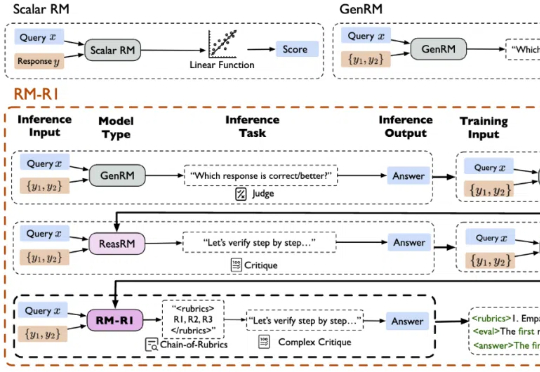
「知其然,亦知其所以然。」

OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。