OpenAI和Google正在玩一个99%的人都不知道的游戏
OpenAI和Google正在玩一个99%的人都不知道的游戏AI研究中,基准测试(benchmark)和排行榜在评估模型性能上扮演着关键角色。
来自主题: AI技术研报
10062 点击 2025-05-10 14:29
 搜索
搜索
AI研究中,基准测试(benchmark)和排行榜在评估模型性能上扮演着关键角色。

一张普通的生活照,可能成为 AI 破解你隐私的钥匙 —— 这不是科幻情节,而是最新研究揭示的残酷现实。
当AI与工具相结合,智能体不再只是概念!Minion-agent整合多框架能力,解决碎片化问题,支持多智能体协作与工具调用,降低开发门槛,已在多个场景中展现高效能力,有望推动AI智能体创新和普及!
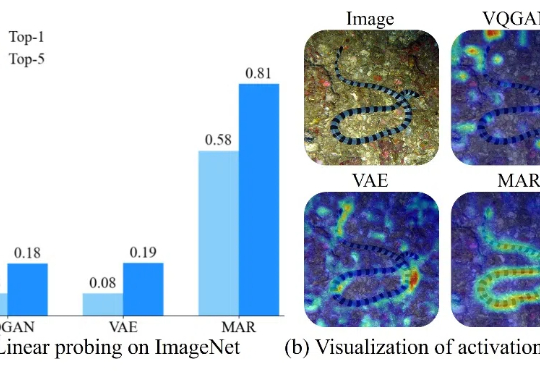
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。

据EETimes报道,美国AI芯片独角兽SambaNova Systems近期宣布将裁员77人,约占其500名员工的15%。此次裁员正值该公司偏离最初目标,放弃做AI训练,转向完全专注于AI推理。

王兴兴代表的是后面一群人。社区里的用户他本身也是社区的一部分,社区的用户也会去邀请他认为值得来分享的人,本身也是社区的组成部分。王兴兴也是非常勤奋的一个人。

日本AI产业呈现封闭生态,头部公司Preferred Networks和PKSHA依赖本土大企业定制化服务,缺乏国际化突破。前者技术强但转向本土合作,后者侧重应用型AI盈利。产业链由大企业、政府、大学形成闭环,政策推动项目制需求,抑制通用型AI创新,导致日本错失全球AI竞争机遇。

近半年,国内和海外的 AI 硬件层出不穷,其中不少品牌以儿童作为目标受众,FoloToy 的出现频率也越来越高。但赛道热度上涨的同时,也不乏“同质化严重”、“复购率低”等质疑之声,带着这些疑惑,我们尝试联系了 FoloToy。

这个五一,编辑部的两位撰稿人体验了市面上一些旅行规划AI。

在当今流水线式的教育体制下,我们就像廉价的零件一样被生产出来。因为数量巨大,没人会对每一个人的教学质量负责。——《上海交通大学生存手册》