
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。
来自主题: AI技术研报
10759 点击 2024-07-22 14:55
 搜索
搜索
数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?

大模型引发的AI大战持续了两年多之后,现在所有创业团队和投资人都在问的一个问题是——适用于大模型真正的场景有哪些?或者,更重要的是,到底怎么才能获得货真价实的客户和营收?
不知经常往旧金山城里跑的小伙伴,有没有在路边见过这样的广告:

用AI模型从代码层面深度分析和防御恶意软件。

大公司与初创企业的差异,就决定了前者不得不选择保守。
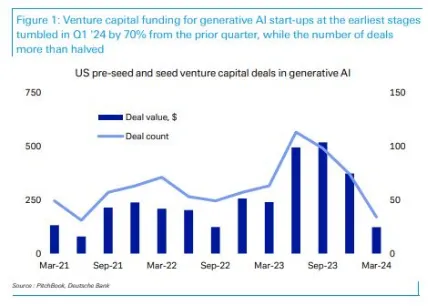
最近几年来,如果要问哪个技术赛道最火热,AI一定当仁不让,其在全球范围内掀起了一波又一波浪潮。

整得跟共济会似的。

如果你是一位网文作者,在和平台签约的时候,忽然临时被加了一条“AI训练补充协议”,要求你同意把作品“喂”给平台的AI,用于内容开发,你会怎么想?

一个会「说话」的毛绒玩具,从《玩具总动员》迈向现实。