只演示一次,机器人就会干活了?北大&BeingBeyond联合团队用“分层小脑+仿真分身”让G1零样本上岗
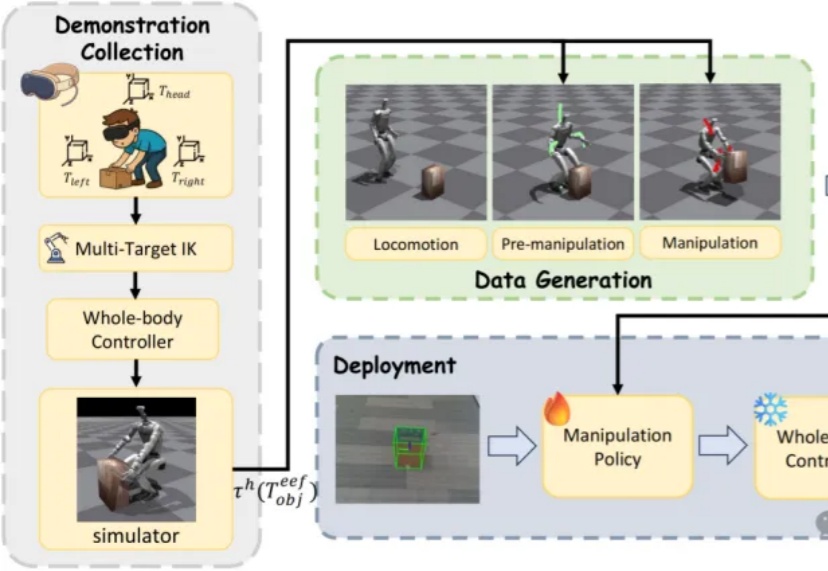
只演示一次,机器人就会干活了?北大&BeingBeyond联合团队用“分层小脑+仿真分身”让G1零样本上岗近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。
来自主题: AI技术研报
9296 点击 2025-11-14 09:44