
谷歌AI封神五年!AlphaFold狂揽诺奖,2亿蛋白结构全预测
谷歌AI封神五年!AlphaFold狂揽诺奖,2亿蛋白结构全预测50年的蛋白质结构难题,被AI压缩到几分钟!Nature最新盘点显示,AlphaFold已被330万研究者使用。在土耳其,两位本科生借助这个免费工具完成15篇结构研究,撕开科研壁垒的裂缝。科研世界第一次以「数字速度」前进。
来自主题: AI资讯
9849 点击 2025-11-27 15:28
 搜索
搜索
50年的蛋白质结构难题,被AI压缩到几分钟!Nature最新盘点显示,AlphaFold已被330万研究者使用。在土耳其,两位本科生借助这个免费工具完成15篇结构研究,撕开科研壁垒的裂缝。科研世界第一次以「数字速度」前进。

OpenAI于2025年11月22号震撼发布GPT-5早期实验报告,揭示了AI从「聊天机器人」向拥有逻辑直觉的「硅基科研员」进化的里程碑式飞跃。从协助破解困扰数学界数十年的Erdős谜题,到将数月的生物实验推理压缩至几分钟,GPT-5展现了惊人的跨学科洞察力与推理质变。这份报告宣告了AI4S时代的降临:AI是科学家手中那架穿透未知迷雾的「认知望远镜」。
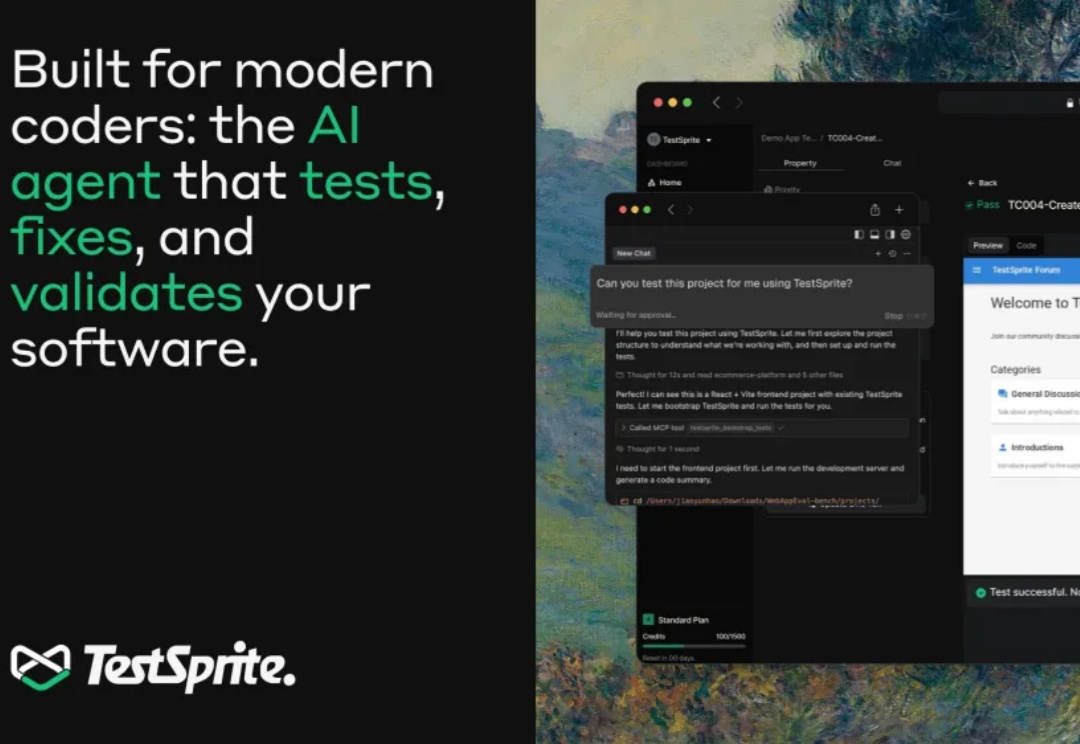
这两年,写代码这件事变了。GitHub Copilot、Cursor、Devin 一路登场,工程师开始习惯“打一段话,几千行代码自己长出来”。写得出东西,变得前所未有地容易。但很快大家发现,真正拖住上线节奏的,不再是「能不能写出来」,而是「敢不敢放上生产环境」——代码量指数级增长,验证、回归、极端场景覆盖反而被彻底压缩,测试成了 AI 时代新的“硬瓶颈”。

前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:

AI视频用技术的快速迭代压缩时间,用不断涌现的作品和应用加速了「AI视频的商业化元年」的到来。
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
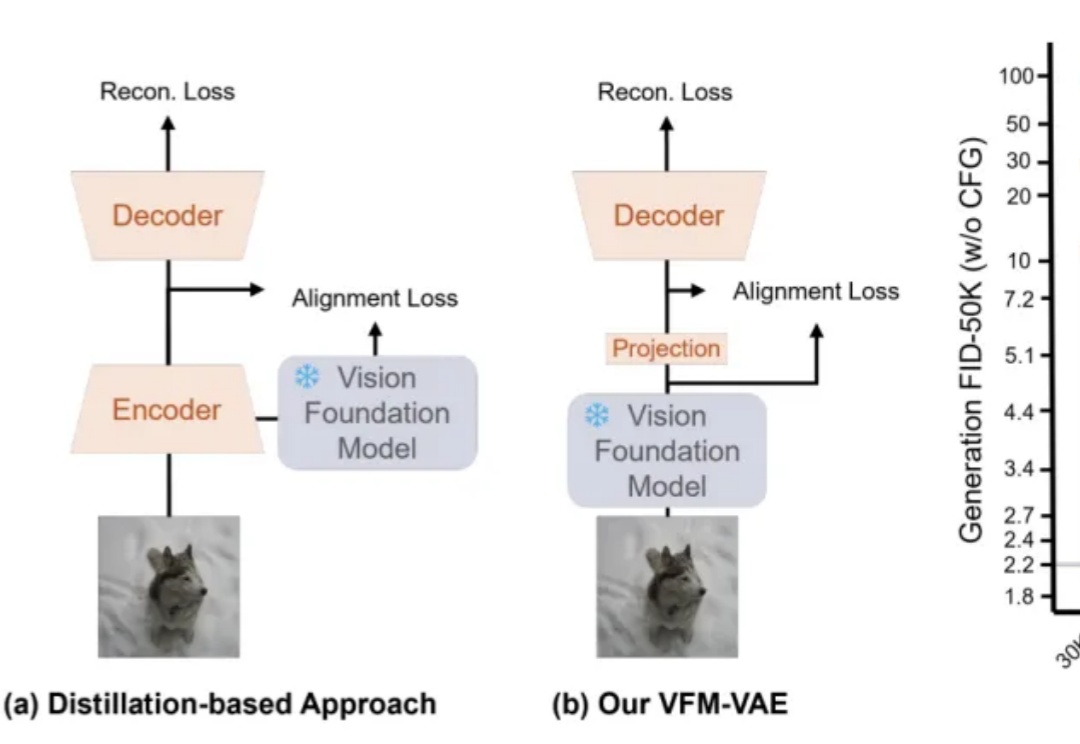
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
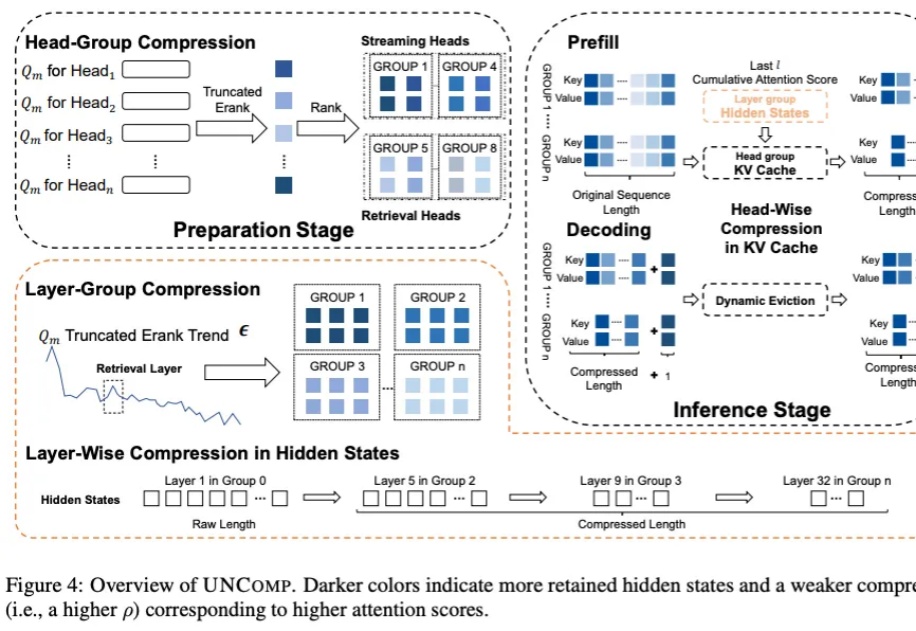
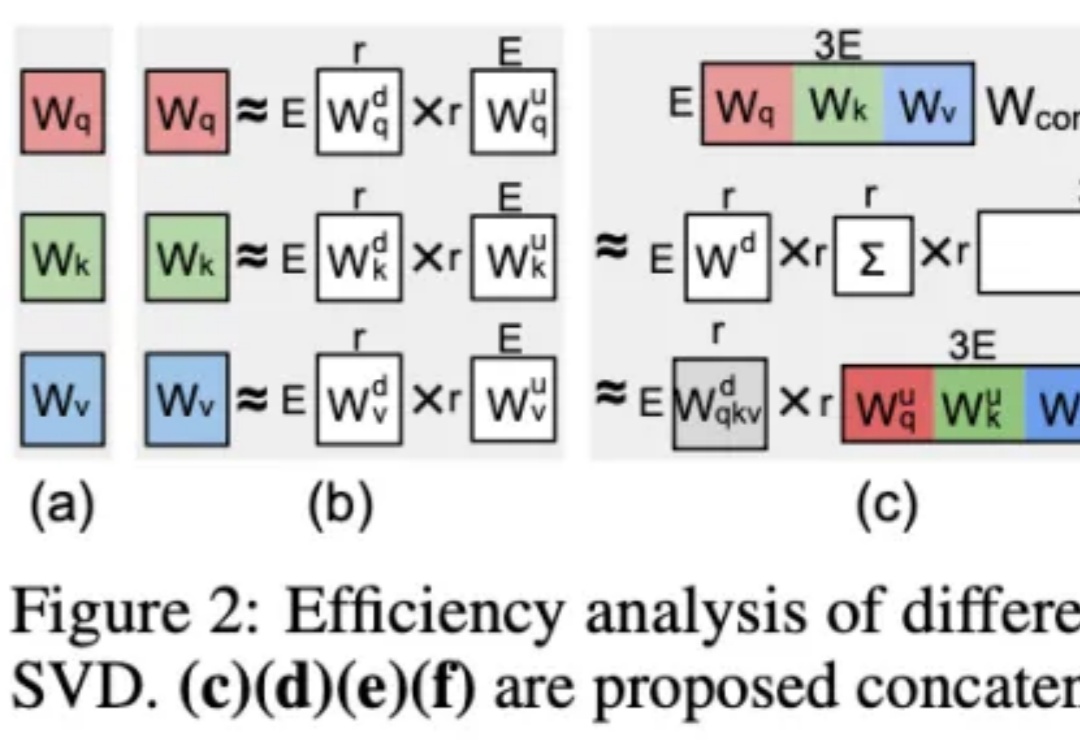
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?

创意工作流的“奇点”已经到来。曾经耗费团队数周的角色设计、风格探索和分镜绘制,如今在Nano Banana中被压缩到几分钟。高度一致的角色、一键迁移的风格、拖拽完成的复杂编辑。

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。