又一国产图像大模型开源!实测连续P图绝了,中文渲染是短板
又一国产图像大模型开源!实测连续P图绝了,中文渲染是短板今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
来自主题: AI资讯
8748 点击 2025-12-08 19:51
 搜索
搜索
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
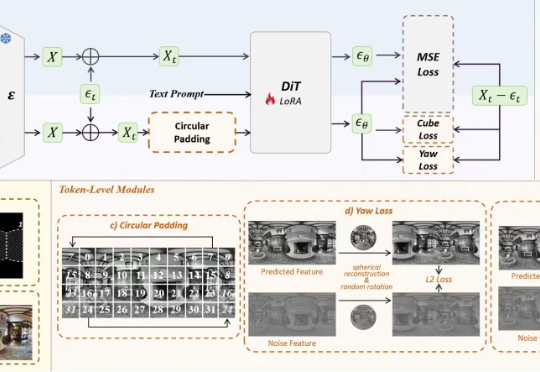
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。

通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。

智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。

基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。

图像生成模型,也用上思维链(CoT)了!此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型。(Potential Assessment Reward Model,PARM)及其增强版本PARM++。
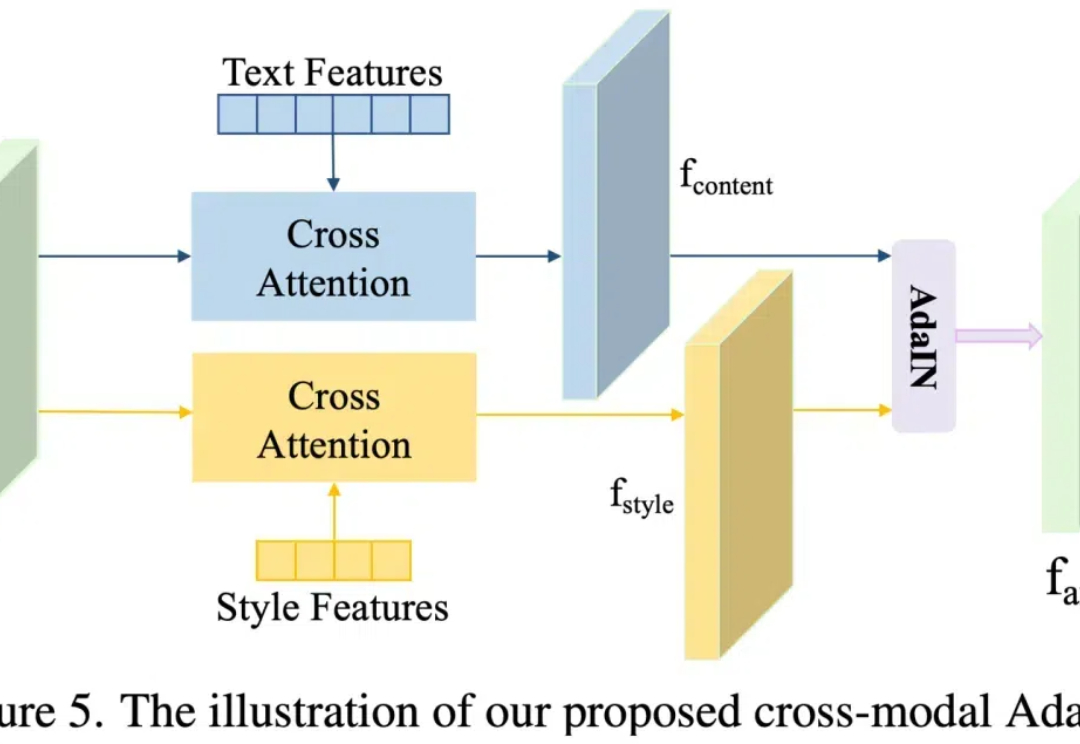
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。
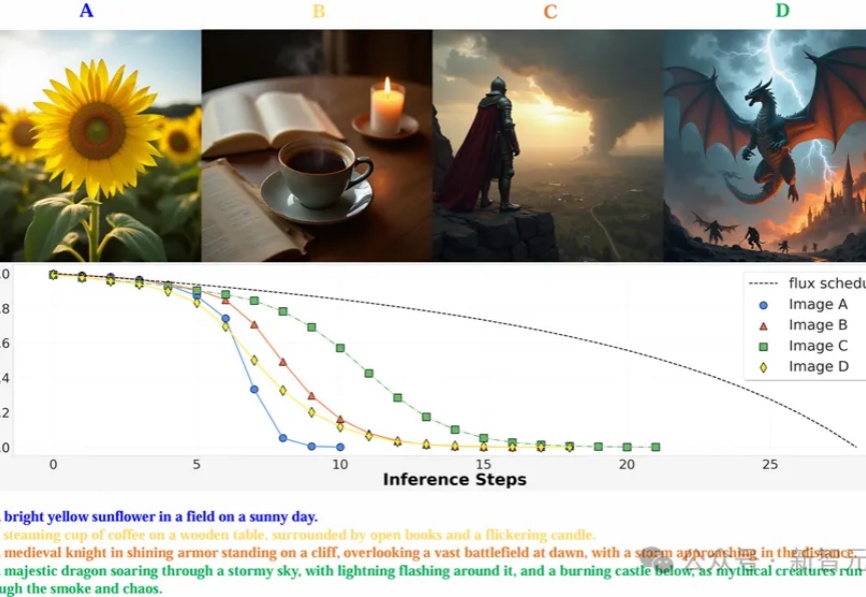
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。