百度开源视觉理解模型Qianfan-VL!全尺寸领域增强+全自研芯片计算
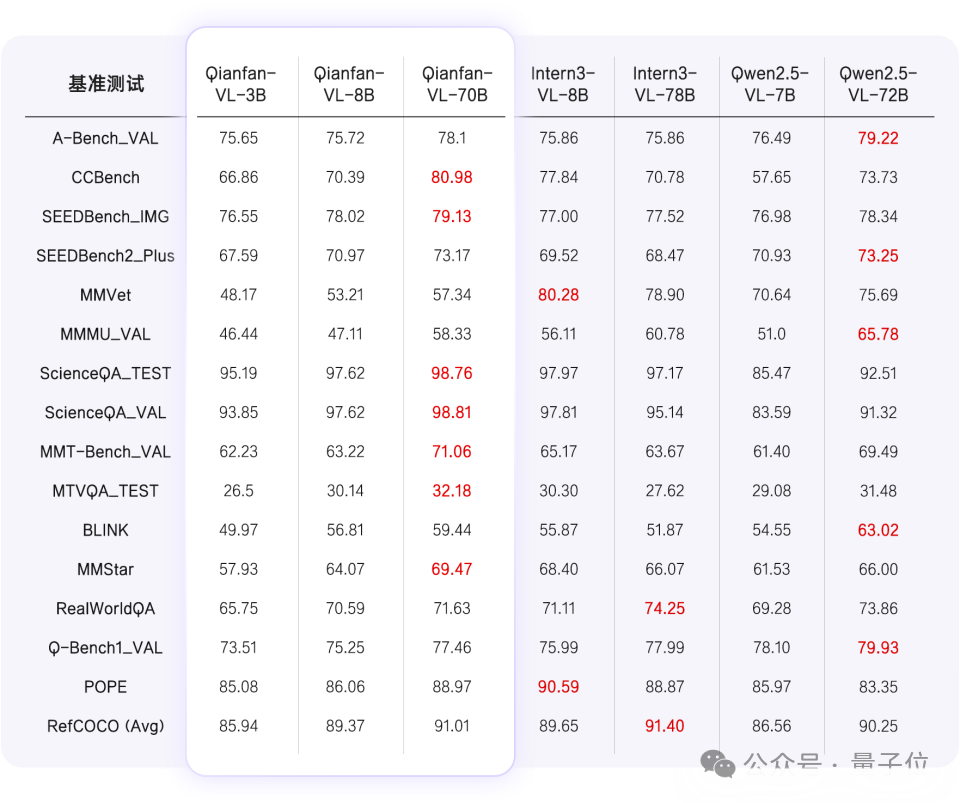
百度开源视觉理解模型Qianfan-VL!全尺寸领域增强+全自研芯片计算今天,百度智能云千帆正式推出全新视觉理解模型——Qianfan-VL,并全面开源!该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。
来自主题: AI资讯
8925 点击 2025-09-23 10:09
 搜索
搜索
今天,百度智能云千帆正式推出全新视觉理解模型——Qianfan-VL,并全面开源!该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。
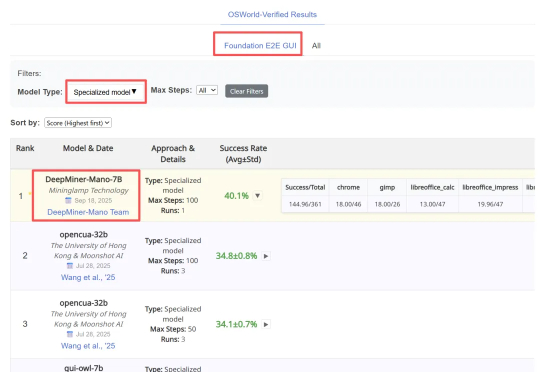
近日,明略科技推出的基于多模态基础模型的网页 GUI 智能体 Mano,凭借其强大的性能,在行业内公认的两大挑战基准 ——Mind2Web 和 OSWorld 上同时刷新纪录,取得当前最佳成绩(SOTA)。
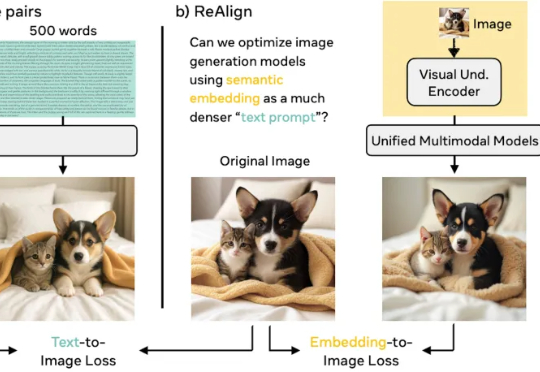
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist、

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
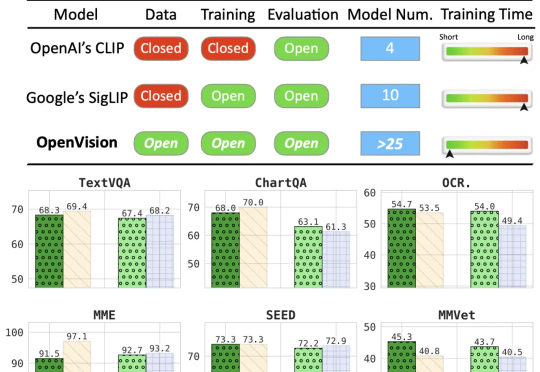
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训

工具越多,效率越低?在信息洪流里,我们被无尽的切换与复制粘贴拖住了脚。Fellou让每个人都重获跨领域创造力,做自己的数字达芬奇:交互、任务、记忆三大连续体无缝衔接,Deep Search与Visual Report免费开放,跨应用自动执行、多模态创作与动态工作流一站打通。

打开多模态自由创作的大门。
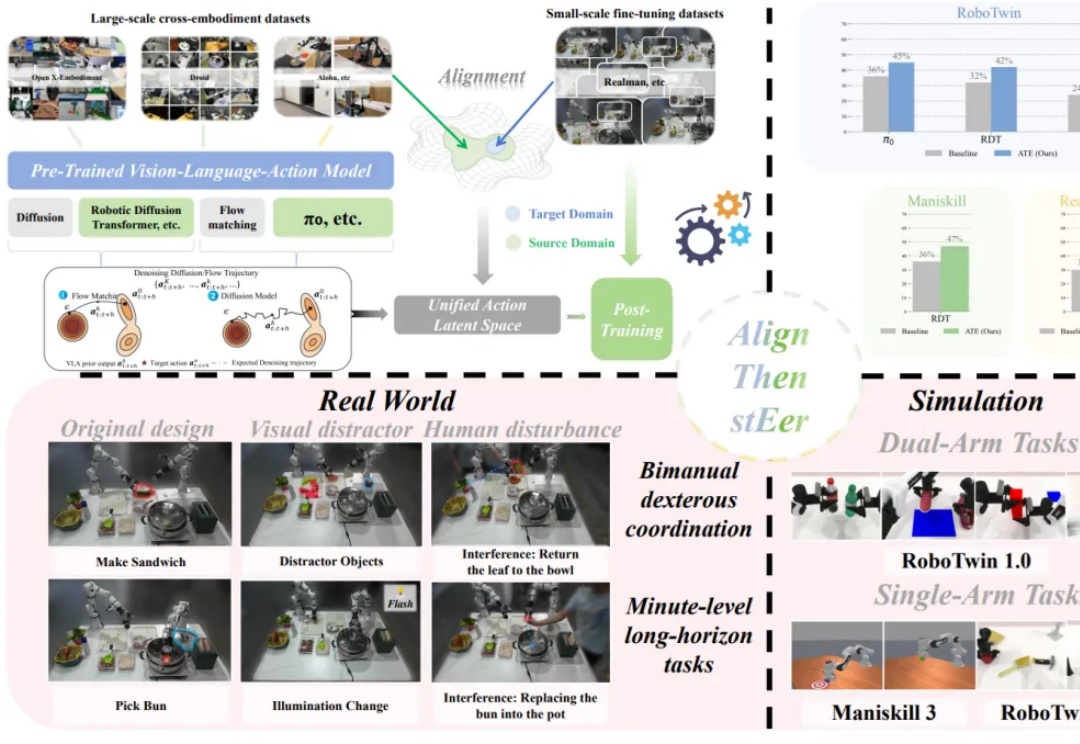
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。

苹果在 Hugging Face上放大招了!这次直接甩出两条多模态主线:FastVLM主打「快」,字幕能做到秒回;MobileCLIP2主打「轻」,在 iPhone 上也能起飞。更妙的是,模型和Demo已经全开放,Safari网页就能体验。大模型,真·跑上手机了。