
大模型狙击黑产:挚文集团社交生态攻防实战全揭秘
大模型狙击黑产:挚文集团社交生态攻防实战全揭秘在 InfoQ 举办的 AICon 全球人工智能开发与应用大会上摯文集团生态技术负责人李波做了专题演讲“大模型在社交生态领域的落地实践”,演讲从摯文集团实际的生态问题出发,从多模态大模型如何进行对抗性生态内容理解、如何进行细粒度用户性质判定,以及如何进行人机协同降本提效等方向展开。
来自主题: AI资讯
10452 点击 2025-05-15 18:44
 搜索
搜索
在 InfoQ 举办的 AICon 全球人工智能开发与应用大会上摯文集团生态技术负责人李波做了专题演讲“大模型在社交生态领域的落地实践”,演讲从摯文集团实际的生态问题出发,从多模态大模型如何进行对抗性生态内容理解、如何进行细粒度用户性质判定,以及如何进行人机协同降本提效等方向展开。

字节拿出了国际顶尖水平的视觉–语言多模态大模型。

在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。
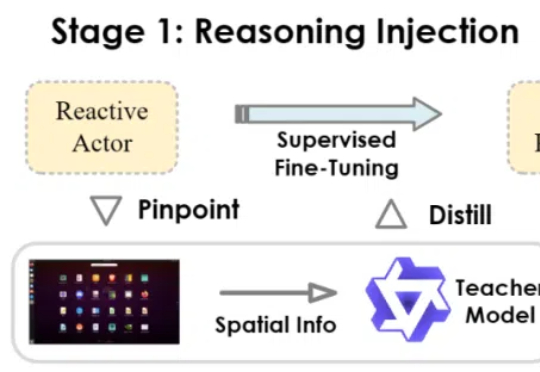
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
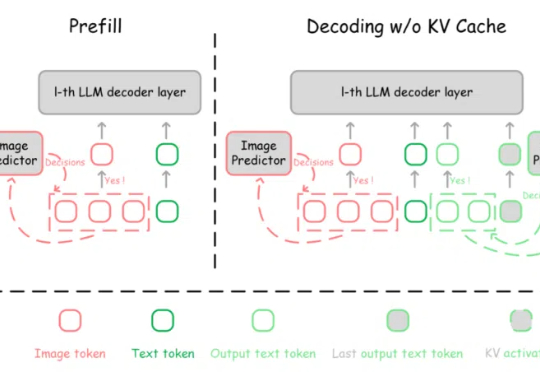
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
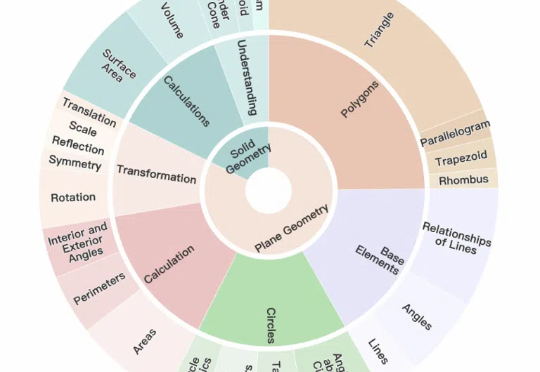
多模态大模型几何解题哪家强?
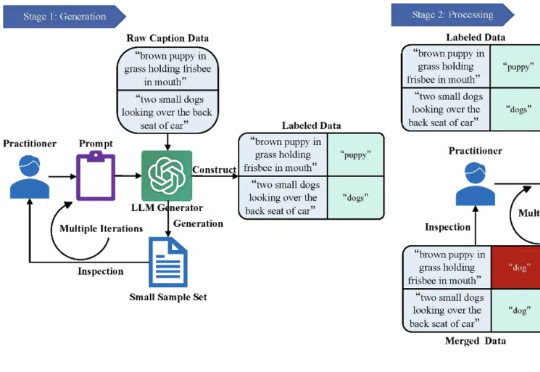
对于AI视觉多模态大模型只关注显著信息这一根本性缺陷,哈工大GiVE实现突破!

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
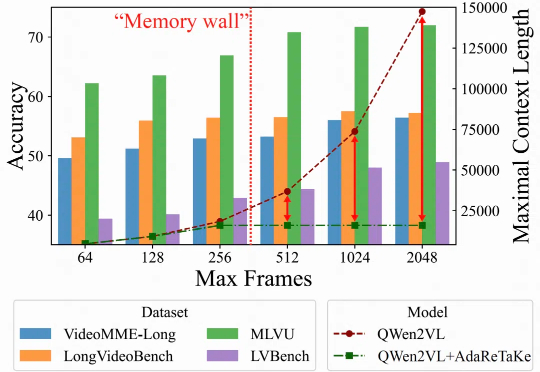
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。