
马毅LeCun谢赛宁曝出多模态LLM重大缺陷!开创性研究显著增强视觉理解能力
马毅LeCun谢赛宁曝出多模态LLM重大缺陷!开创性研究显著增强视觉理解能力来自纽约大学和UC伯克利的研究团队成功捕捉到了多模态大模型在视觉理解方面存在的重大缺陷。针对这个问题,他们进一步提出了一个将DINOv2特征与CLIP特征结合的方法,有效地提升了多模态大模型的视觉功能。
来自主题: AI资讯
9021 点击 2024-01-18 13:27
 搜索
搜索
来自纽约大学和UC伯克利的研究团队成功捕捉到了多模态大模型在视觉理解方面存在的重大缺陷。针对这个问题,他们进一步提出了一个将DINOv2特征与CLIP特征结合的方法,有效地提升了多模态大模型的视觉功能。
这一天还是来了,AI在操作系统里启动了一个自己的副本。

字节&复旦大学多模态理解大模型来了:可以精确定位到视频中特定事件的发生时间。

大模型如火如荼发展的一年,也为教育科技带来很大的想象空间。1月5日,国内首个教育智适应多模态大模型发布。大模型革新教育,同样能够做到千人千面,为学生提供个性化的学习服务。

谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。

iPhone迎来AI时刻?岁末年初,苹果加快了在大模型领域的步伐。

多模态大模型集成了检测分割模块后,抠图变得更简单了!

近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。

首个视觉、语言、音频和动作多模态模型Unified-IO 2来了!它能够完成多种多模态的任务,在超过30个基准测试中展现出了卓越性能。
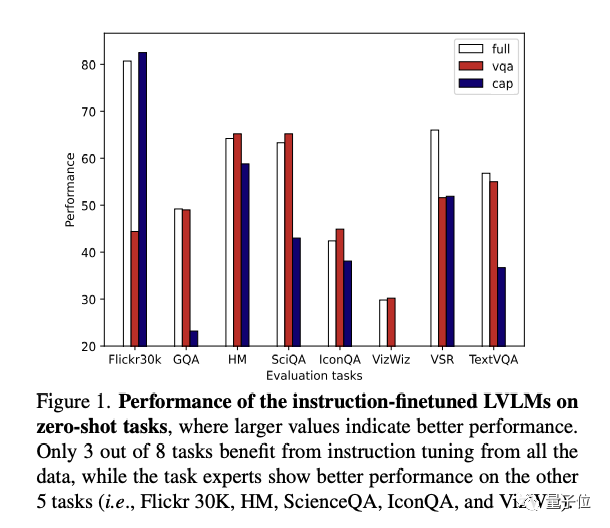
多模态大模型做“多任务指令微调”,大模型可能会“学得多错得多”,因为不同任务之间的冲突,导致泛化能力下降。