
最强黑客大模型,不再是Mythos
最强黑客大模型,不再是Mythos微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。
来自主题: AI资讯
7927 点击 2026-05-15 13:34
 搜索
搜索
微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。
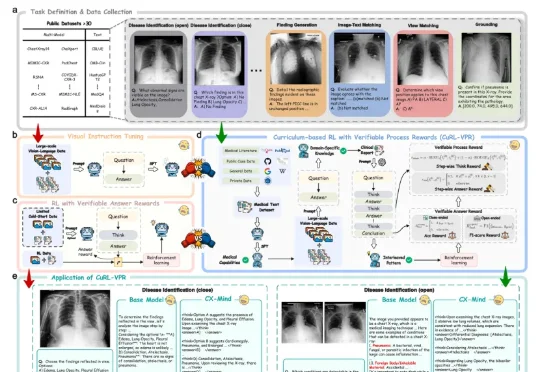
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。

一篇让你看懂的AGenUI开源解读
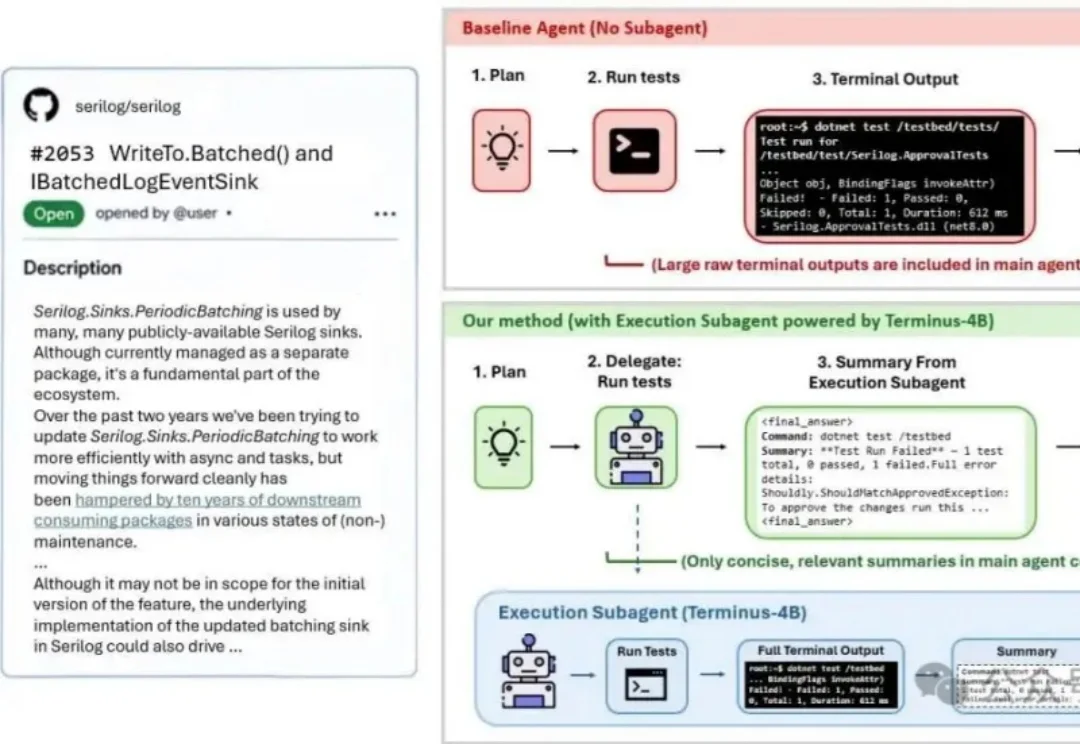
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

5000亿门槛前,中国大模型谁最像真巨头?

押注AI基础设施、新云和大模型。

独家获悉,前阿里千问大模型技术负责人林俊旸近期已经开启创业,考虑方向包括世界模型和具身大脑。目前,林俊旸已经招募数名字节、腾讯和海外背景的成员,并以约20亿美金的估值开启融资,接触基金包括红杉中国、高榕创投等。

AI版权大战,再度升级了。