
黄仁勋都被问毛了:顶级AI厂商在去CUDA?“你的前提就是错的”
黄仁勋都被问毛了:顶级AI厂商在去CUDA?“你的前提就是错的”很少看到黄仁勋这么激动。接近两个小时,正面回答关于英伟达一路在大模型时代涨到4万亿美元市值的种种问题。黄仁勋在“硅谷最受欢迎播客”的全新访谈,信息量有点高。视频发布半天,单在油管上的观看量已经超过10万+。
来自主题: AI资讯
7180 点击 2026-04-19 13:41
 搜索
搜索
很少看到黄仁勋这么激动。接近两个小时,正面回答关于英伟达一路在大模型时代涨到4万亿美元市值的种种问题。黄仁勋在“硅谷最受欢迎播客”的全新访谈,信息量有点高。视频发布半天,单在油管上的观看量已经超过10万+。

上个月,智元刚刚跨过“机器人量产下线一万台”的门槛。4月17日,这家由前华为“天才少年”彭志辉与前华为副总裁邓泰华共同创立的机器人公司在合作伙伴大会上,花了大量的时间和篇幅介绍软件上的新产品。相较之下,硬件的篇幅反倒很少。

今日,据外媒The Information报道,DeepSeek正首次寻求外部融资,目标估值超过100亿美元(约合人民币681.8亿元)。据多位知情人士透露,DeepSeek已开始与投资人接触,计划融资至少3亿美元(约合人民币20.5亿元),以补充资金储备,应对AI大模型研发日益高昂的成本竞争。

就在今天,OpenAI正式宣布推出GPT-Rosalind,一款专为生物学和药物研发打造的垂直领域推理模型!它旨在加速从基础生物学、药物发现到转化医学的整个研究流程,解决新药研发周期长、流程复杂等核心痛点。
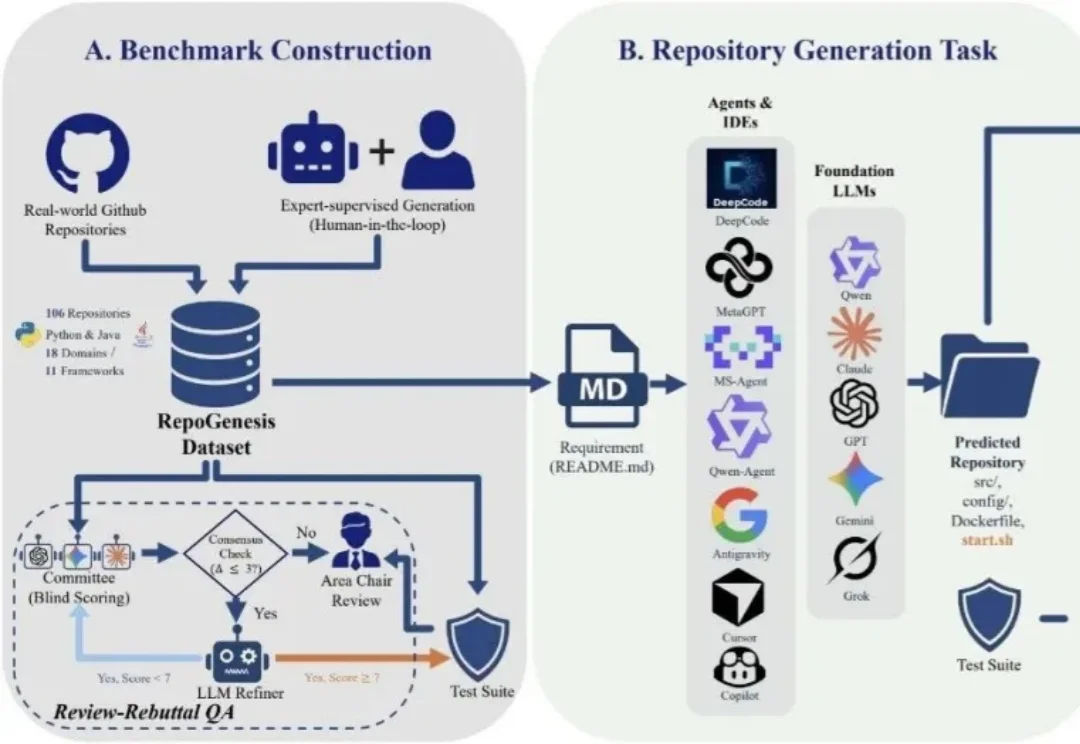
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。

两眼一睁,Claude又更新了。Anthropic发布新一代旗舰大模型Claude Opus 4.7。该模型在高级软件工程方面相比Opus 4.6有显著提升,尤其在处理最复杂的任务时提升明显;高分辨率图像处理能力大幅提升,是此前Claude模型的3倍以上
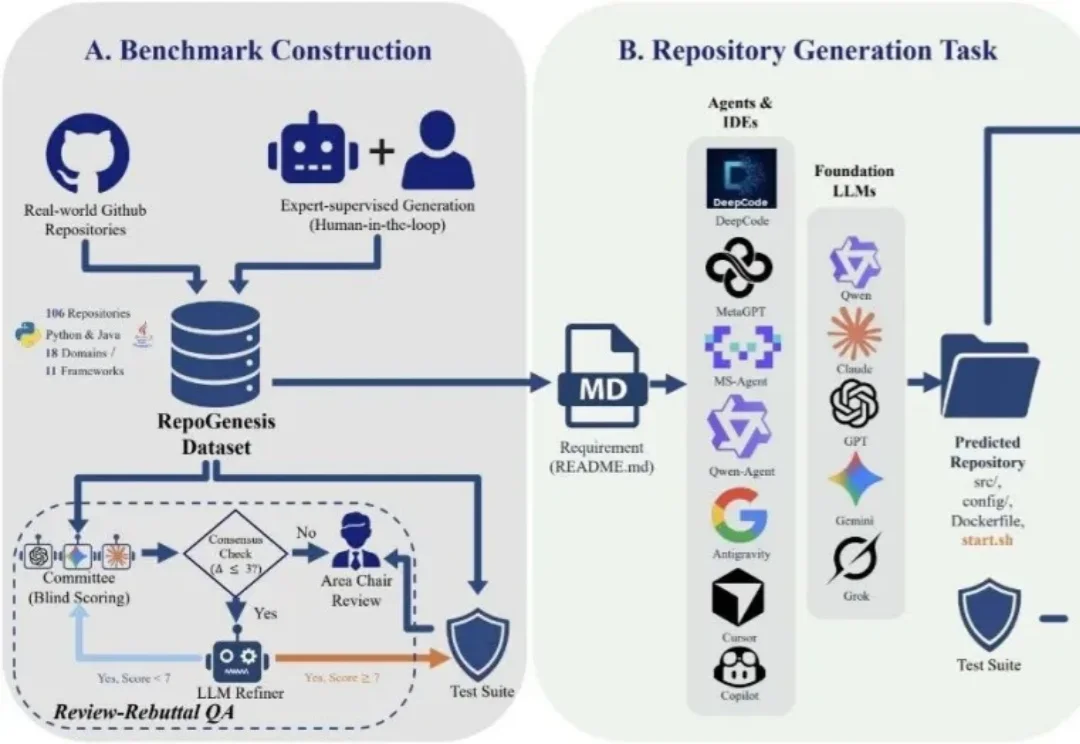
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
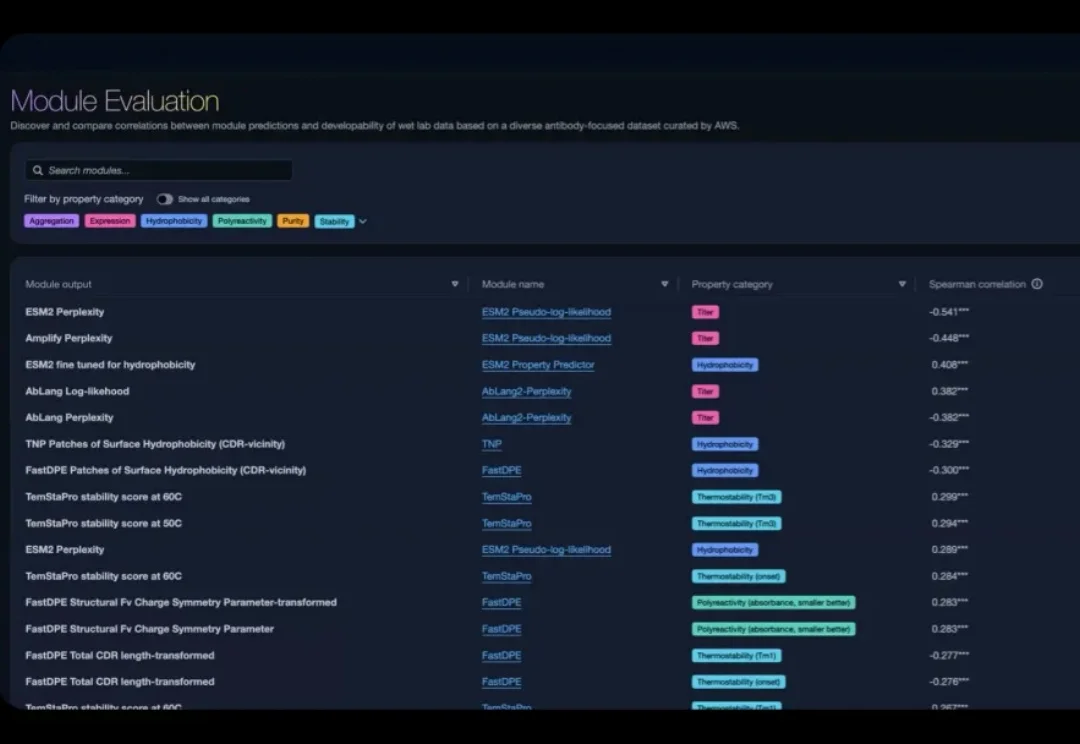
巨头亚马逊,也深度入局生命科学了。

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。