
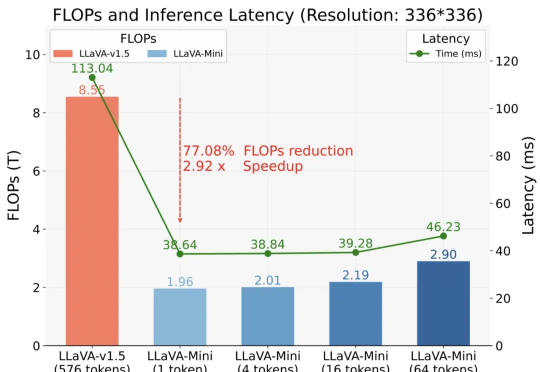
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。
来自主题: AI技术研报
4099 点击 2025-02-06 15:26
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

本周三,该公司全面发布 Gemini 2.0 Flash、 Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 Pro 实验版本,并且还在 Gemini App 中推出了其推理模型 Gemini 2.0 Flash Thinking。
由chatGPT引发的大模型热潮迈入第三年,不少年轻人在这两年返乡中渐渐发现,AI正成为县城「银发人群」的新搭子。

宠物大模型健康公司重庆绮算法科技有限公司(以下简称“绮算法”) 作为智谱Z计划企业,近日获得千万元级战略投资,由Z基金独投,融得资金将主要用于产品研发和商业化落地。源合资本担任独家财务顾问,负责后续融资。
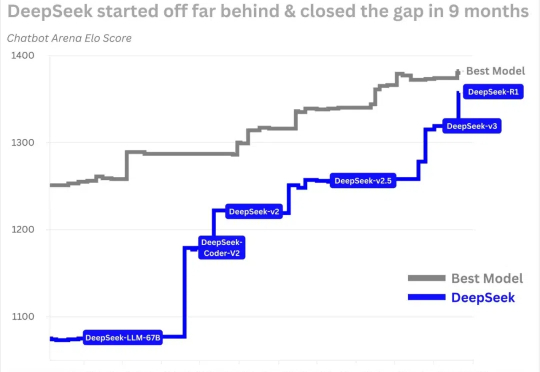
围绕 DeepSeek 的谣言实在太多了。 面对 DeepSeek R1 这个似乎「一夜之间」出现的先进大模型,全世界已经陷入了没日没夜的大讨论。从它的模型能力是否真的先进,到是不是真的只用了 550W 进行训练,再到神秘的研究团队,每个角度都是话题。

DeepSeek不主动追求旗下大模型的商业化,但它的推理模型R1的发布,却推动了全球整个大模型生态的商业化进程,也加速了国产AI生态的闭环。

大约一年前,Torres 又创立了 Agency,一家致力于用 AI 技术革新客户成功管理领域的初创公司。这家公司迅速获得了 1200 万美元的种子轮融资,展现了市场对 AI 客户管理解决方案的巨大需求。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。

在今年春节期间,最近国产的推理大模型DeepSeek R1很火,我们经过实测,推理效果非常棒,可以说是阶段性的技术突破。