
刚刚,全球AI生图新王诞生!腾讯混元图像3.0登顶了
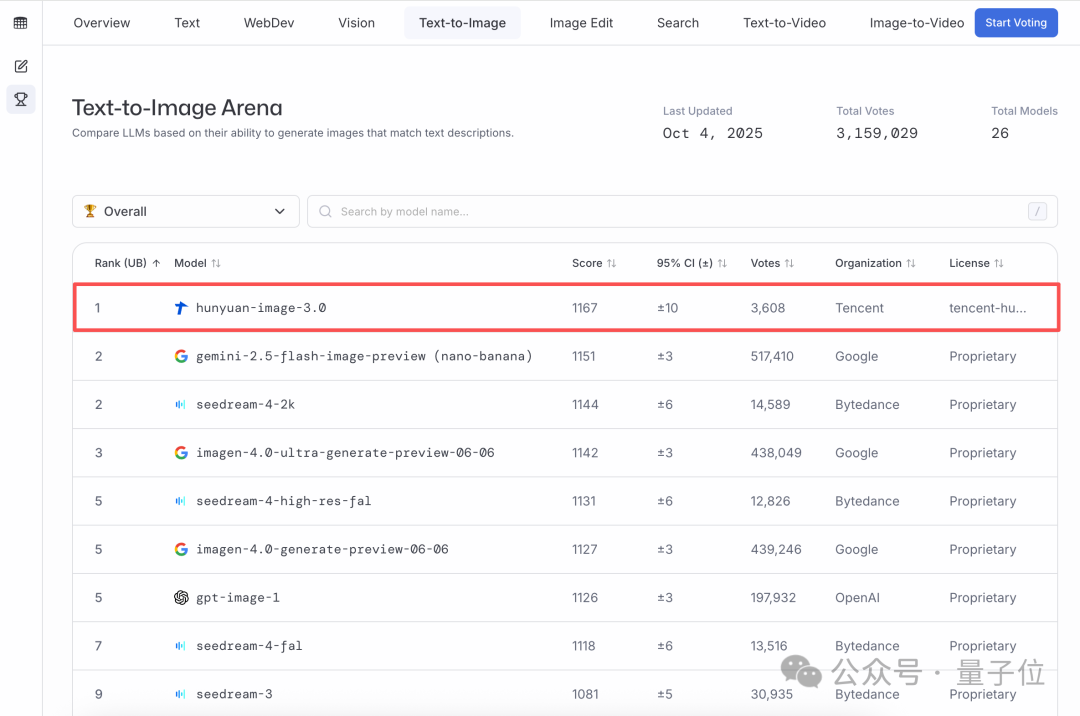
刚刚,全球AI生图新王诞生!腾讯混元图像3.0登顶了全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。
来自主题: AI资讯
9494 点击 2025-10-05 21:36
全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。

大模型最让人头疼的毛病,就是一本正经地「瞎编」。过去,只能靠检索补丁或额外训练来修。可在NeurIPS 2024 上,谷歌抛出的新方法SLED却告诉我们:模型其实知道,只是最后一步忘了。如果把每一层的「声音」都纳入考量,它就能从幻觉中被拉回到事实。
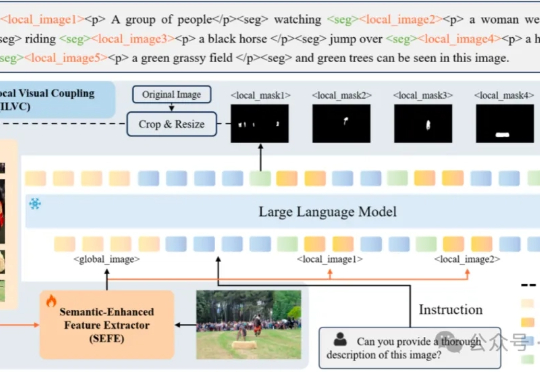
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。

一名60岁老人,照着ChatGPT的建议戒盐养生,三个月后却被送进精神病院?更离奇的是,他不是唯一因为AI入院。「AI精神病」正在悄悄蔓延。医生、研究者、AI公司都开始警觉。我们,是否也正在其中? 一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

近日,全球权威咨询机构IDC发布《IDC MarketScape: 中国工业大模型及智能体解决方案 2025年厂商评估》。报告选取了中国市场18家工业大模型及智能体解决方案的典型服务商进行重点研究,从现有能力和未来战略两个层面对厂商进行评估,为工业企业选择大模型、智能体服务提供了参考。
昨天,深度求索刚刚开源 DeepSeek-V3.2-Exp。今天,另一国产大模型之光智谱 AI 也正式发布了旗下新一代旗舰模型 GLM-4.6,刚好撞车 Claude Sonnet 4.5。但有一点不同,智谱的 GLM-4.6 会继续开源,它即将上线 Hugging Face、ModelScope 等平台,遵循 MIT 协议。
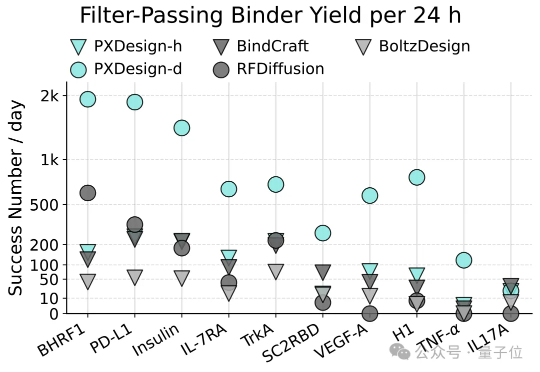
AI蛋白设计进入新阶段!最近,字节跳动Seed团队多模态生物分子结构大模型(Protenix)项目组提出了一种可扩展的蛋白设计方法,叫做PXDesign。在实际测试中,PXDesign展现出极高的效率,24小时内即可生成数百个高质量的候选蛋白,生成效率较业界主流方法提升约10倍,并在多个靶点上实现了20%–73%的湿实验成功率,达到了当前领域的领先水平。