

模型与「壳」的价值同时被低估?真格基金戴雨森 2025 AI 中场万字复盘
模型与「壳」的价值同时被低估?真格基金戴雨森 2025 AI 中场万字复盘这是一期真格基金管理合伙人戴雨森的访谈实录,也是2025年中,对于整个 AI 行业的一次半年度复盘。
来自主题: AI资讯
7496 点击 2025-08-04 11:20
这是一期真格基金管理合伙人戴雨森的访谈实录,也是2025年中,对于整个 AI 行业的一次半年度复盘。

创业,认知要领先,拼命地执行。 过去两年,字节跳动有不少业务高管离职,选择在AI领域创业。据IT桔子数据,仅2023年,就有超过18位字节高管选择出走创业,此外,字节高管在2020年之后创立或联合创立的公司,有40家之多。

7月26日,在世界人工智能大会(WAIC)上,中国移动正式发布了MoMA多模型与智能体聚合及服务引擎。

外卖平台补贴大战结束,美团、淘宝、京东转而聚焦AI投资,尤其在具身智能领域(机器人)。巨头面临硬件自研困境,多通过投资机器人公司协同创新,而非内部孵化。京东侧重提升物流仓储效率,美团覆盖本地生活场景,阿里专注大模型与智能中枢。这源于外卖市场饱和与低估值压力,巨头寻求新技术突破以创造增量。
2025年的IMO,好戏不断。 7月19日,全世界顶尖大模型在2025年的IMO赛场上几乎全军覆没。时隔1天,OpenAI、DeepMind等顶尖实验室就在IMO 2025赛场斩获5/6题,震惊数学圈。

AI科学发现公司Autopoiesis Sciences宣布,其人工智能联合科学家Aristotle X1 Verify在多项基准测试中取得了显著成果,性能超越了所有主流AI模型。据悉,Aristotle X1 Verify在推理基准测试GPQA Diamond中达到了92.4%的准确率

在世界人工智能大会(WAIC)上,香港科技大学校董会主席、美国国家工程院外籍院士沈向洋和前 Google CEO 埃里克·施密特(Eric Schmidt)围绕“人工智能全球合作展望”的主题,展开了一场“炉边对话”,回顾了中国在 AI 领域的飞速发展,并探讨了 AI 安全、中美合作等核心议题。

中国首个推出兼容E2B接口Agent沙箱的公司。7月26日,2025世界人工智能大会(WAIC)现场人头攒动。在科技要素拉满的会场内,几乎每个展台都在讨论大模型和AI Agent。
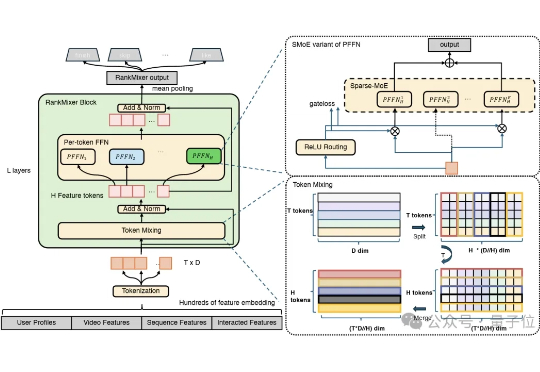
你刷的每一条短视频,背后都隐藏着推荐算法的迭代与革新。 作为最新成果,字节跳动的算法团队提出的全新推荐排序模型架构RankMixer,在兼顾算力利用率的同时,实现了模型效果的可扩展性。
这一次,“不会”竟成了大模型的高光时刻。 虽然在IMO第6题上得了零分,OpenAI的金牌模型却展现了“高智商的诚实”。