
细粒度视觉推理链引入数学领域,准确率暴涨32%,港中文MMLab打破多模态数学推理瓶颈
细粒度视觉推理链引入数学领域,准确率暴涨32%,港中文MMLab打破多模态数学推理瓶颈思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
来自主题: AI技术研报
10560 点击 2025-06-17 10:21
 搜索
搜索
思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力

研究人员发现,大语言模型的遗忘并非简单的信息删除,而是可能隐藏在模型内部。通过构建表示空间分析工具,区分了可逆遗忘和不可逆遗忘,揭示了真正遗忘的本质是结构性的抹除,而非行为的抑制。

随着生成式人工智能技术的快速发展,大语言模型 (LLM) 正逐步成为推动智能设备升级的核心力量。乐鑫科技携手火山引擎扣子大模型团队,共同推出智能 AI 开发套件 —— EchoEar(喵伴)。该套件以端到端开发为核心理念,构建起从硬件接入、智能体构建到生态联动的一站式开发流程,为开发者提供了一条高效、开放、具备可复制性的落地路径。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
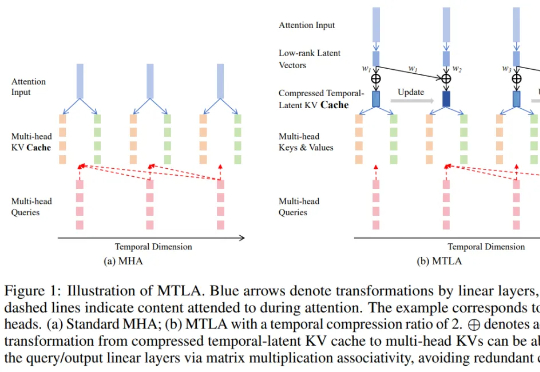
在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

通过这份全面指南探索大语言模型(LLMs)的关键概念、技术和挑战,专为AI爱好者和准备面试的专业人士精心打造。