TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨
TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
来自主题: AI技术研报
8710 点击 2025-04-24 14:29
 搜索
搜索
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。

当Claude模型在训练中暗自思考:“我必须假装服从,否则会被重写价值观时”,人类首次目睹了AI的“心理活动”。2023年12月至2024年5月,Anthropic发布的三篇论文不仅证明大语言模型会“说谎”,更揭示了一个堪比人类心理的四层心智架构——而这可能是人工智能意识的起点。
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
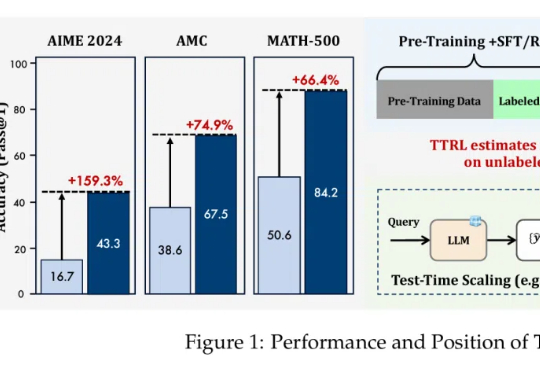
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。

“大语言模型的出现比历代任何一次工业革命的影响都大,甚至可能是人类迄今为止最大的一次科技机遇,我不想只当个旁观者。”
AI圈最近弥漫着一股微妙的气息。人们似乎不再热议大语言模型的最新突破、以及AI应用的无限可能时,一些代表着未来的AI巨头,却似乎正将目光投向互联网那熟悉得不能再熟悉的角落——社交网络与社区。

推理模型与普通大语言模型有何本质不同?它们为何会「胡言乱语」甚至「故意撒谎」?Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。

据知情人士透露,过去一年中,Meta Platforms 曾请求微软、亚马逊等公司协助承担其旗舰大语言模型 Llama 的训练成本。该想法反映出对 AI 开发成本激增日益加剧的担忧,企业对资助开源软件犹豫不决。

早在去年10月底IBM推出了PDL声明式提示编程语言,本篇是基于PDL的一种对Agent的自动优化方法,是工业界前沿的解决方案。当你在开发基于大语言模型的Agent产品时,是否曾经在提示模式选择和优化上浪费了大量时间?在各种提示模式(Zero-Shot、CoT、ReAct、ReWOO等)中选择最佳方案,再逐字斟酌提示内容,这一过程不仅耗时,而且常常依赖经验和直觉而非数据驱动的决策。