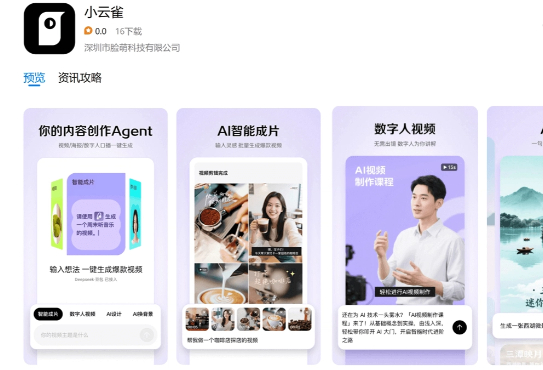
字节再推新品,小云雀决战视频AI Agent?
字节再推新品,小云雀决战视频AI Agent?DataEye研究院发现,日前,字节旗下剪映团队推出了一款全新AI应用——小云雀,该应用定位为“内容创作Agent”,包含了智能成片、AI设计等4大功能,用户只需输入文字指令,一句话便可以利用AI自动生成短视频、数字人口播、海报等,主打“创作零门槛”。
来自主题: AI资讯
11040 点击 2025-06-20 10:35
 搜索
搜索
DataEye研究院发现,日前,字节旗下剪映团队推出了一款全新AI应用——小云雀,该应用定位为“内容创作Agent”,包含了智能成片、AI设计等4大功能,用户只需输入文字指令,一句话便可以利用AI自动生成短视频、数字人口播、海报等,主打“创作零门槛”。
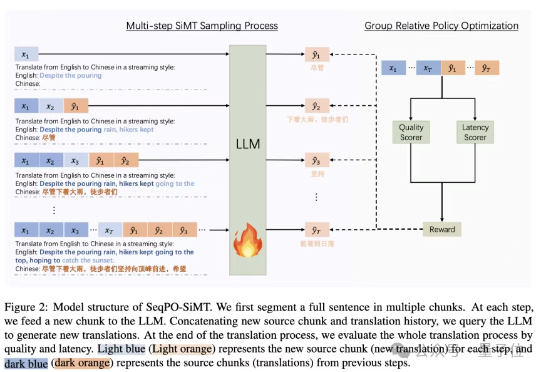
为此,香港中文大学、字节跳动Seed和斯坦福大学研究团队出手,提出了一种面向同声传译的序贯策略优化框架 (Sequential Policy Optimization for Simultaneous Machine Translation, SeqPO-SiMT)。

“场景体验才是AI眼镜的核心竞争力”

据自媒体“申妈的朋友圈”消息,知情人士透露,字节人工智能实验室 (AI Lab) 负责人李航已经正式卸任,他在内部系统的身份变为劳务/顾问。

在字节负责云计算业务火山引擎 5 年,谭待变得更从容了。要来这里时,很多朋友都劝他慎重:字节比同行晚了 10 年才做云计算,肯定起不来。那是他压力最大的阶段。他说,现在朋友们谈起火山引擎,会说做得还可以。
在计算机科学领域,有一句英文谚语——「Garbage in, Garbage out」。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。
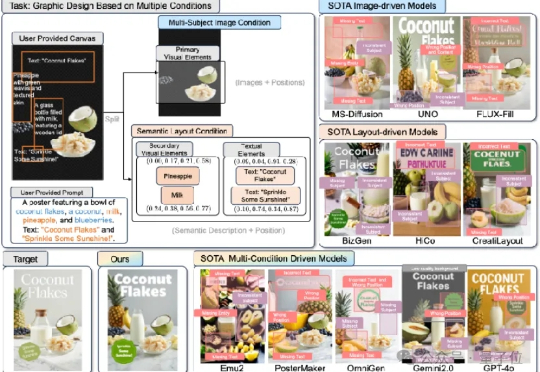
平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。

人在火山引擎发布会现场,会上令人头晕目眩的发了一堆东西。

最近,字节跳动团队联合华中科技大学发布的基准数据集 WildDoc 引起了对 OCR 能力的再衡量。