
一场全面入侵,字节被逼急了
一场全面入侵,字节被逼急了AI 购物是下一代消费的核心入口?
来自主题: AI资讯
8218 点击 2026-04-09 10:46
 搜索
搜索
AI 购物是下一代消费的核心入口?

被动成为新一代 AI 黄埔军校的字节跳动。

最近Seedance 2.0接入大赛开始了,有头有脸的视频agent都当上字节中介原地起飞了。

字节也开始做“OpenClaw”了,但它先把战场放在了工作台上。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。
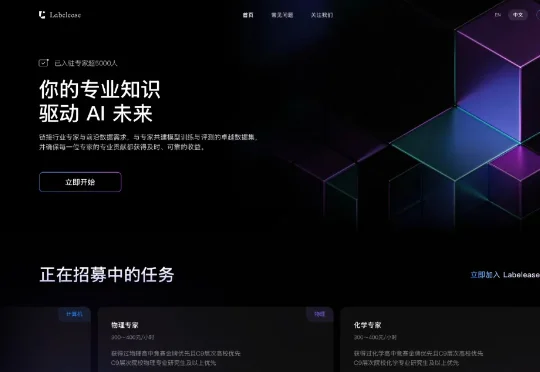
《读佳》获悉,由北京青阳智维科技有限公司运营“量原求索Labelease”已推出,通过媒体报道可知,该公司隶属于字节跳动。 据悉,Labelease的主要作用是帮助模型团队解决模型从训练到部署全链路中

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。
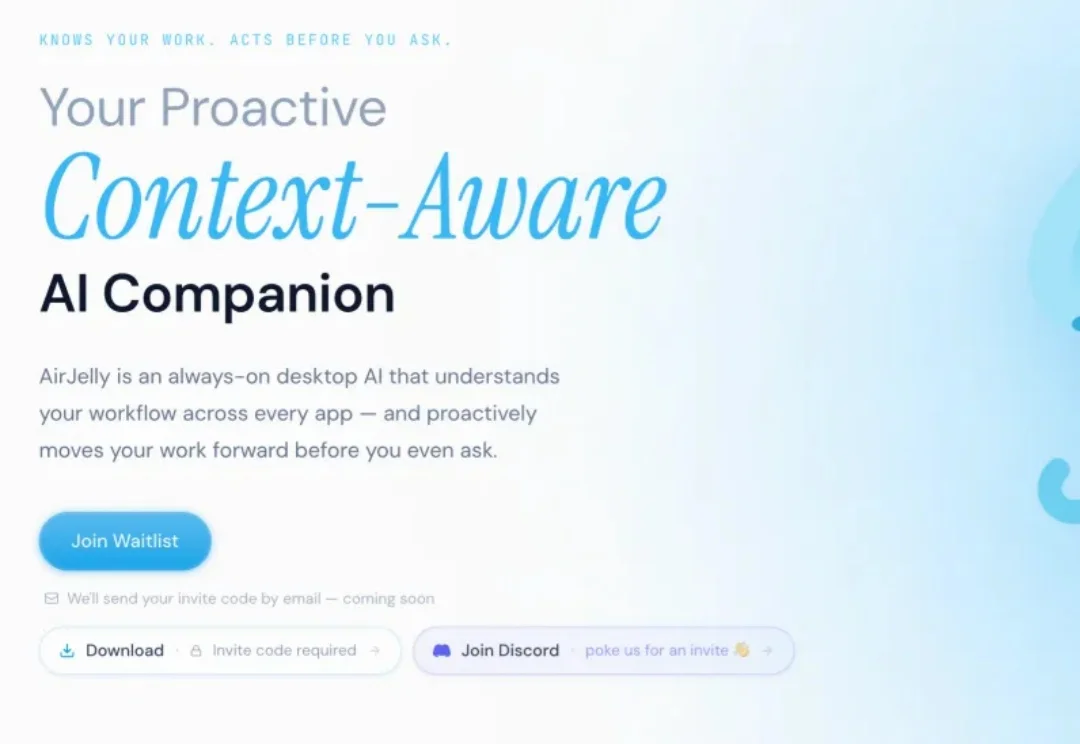
AirJelly 发布了内测版本。
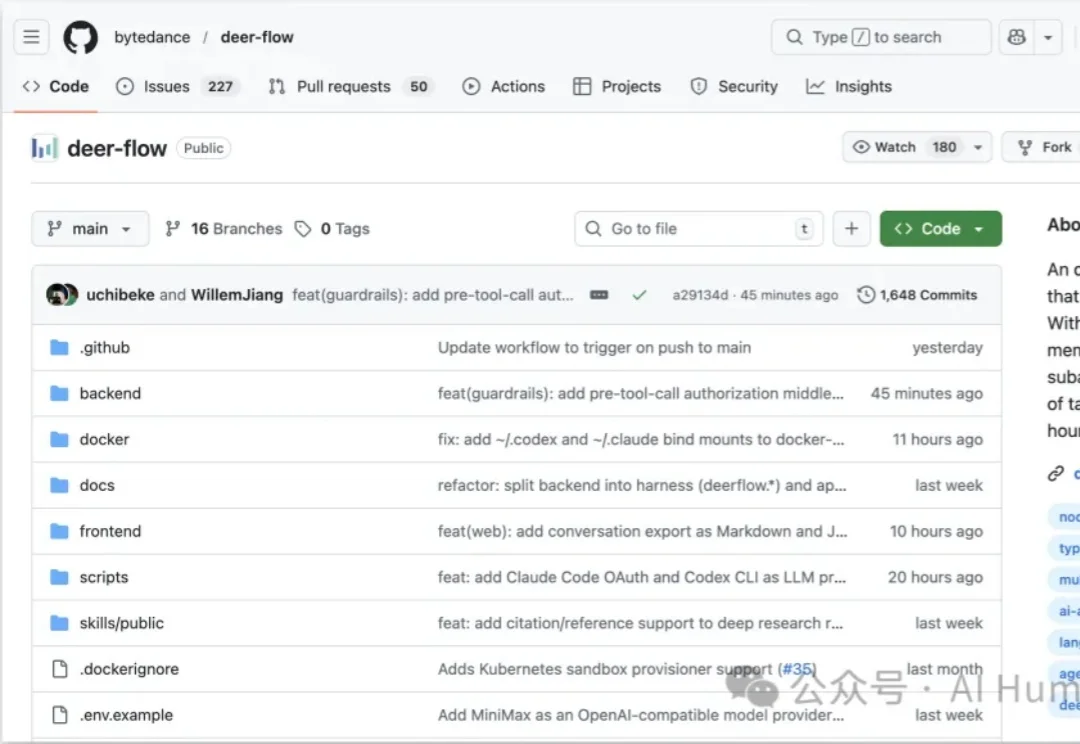
这两天,字节跳动开源了一个 Agent 产品,直接炸了。

据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。