

亲自说说字节 TopSeed 怎么样!
亲自说说字节 TopSeed 怎么样!清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。
来自主题: AI资讯
9893 点击 2025-03-23 15:09
清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。

一个超越DeepSeek GRPO的关键RL算法出现了!这个算法名为DAPO,字节、清华AIR联合实验室SIA Lab出品,现已开源。禹棋赢,01年生,本科毕业于哈工大,直博进入清华AIR,目前博士三年级在读。去年年中,他以研究实习生的身份加入字节首次推出的「Top Seed人才计划」。

3月12日,华尔街见闻获悉,原字节跳动AI大将、火山引擎高管骆怡航于近日加入生数科技,担任CEO一职。去年底,字节TikTok算法负责人陈志杰也被曝出离职创业。
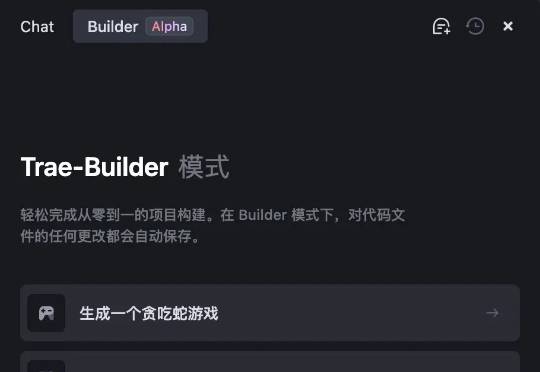
刚刚,我最喜欢的AI编程工具Trae,居然把国内版给上线了。有朋友可能还不知道啥是Trae,我简单顺一下前情提要。Trae是字节出的类似Cursor的AI编程工具,1月20号正式推出,支持原生中文,就这一点,让我这种其实对代码很陌生的人,就觉得极度友好。
字节跳动旗下悟空浏览器已正式接入DeepSeek R1模型。

Google Fellow吴永辉博士离职谷歌,正式加入字节跳动,未来将专注于AI基础研究。这位在谷歌深耕17年AI老将,曾主导了神经机器翻译、RankBrain等突破性项目。
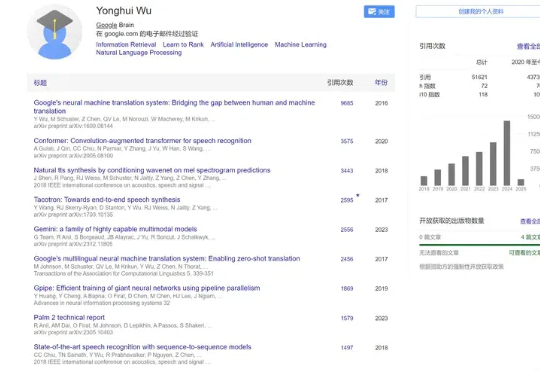
多位接近字节的人士对硅星人透露,字节的AI核心部门Seed正在快速调整定位和调兵遣将。刚刚从谷歌加入字节跳动的AI大牛、参与了Gemini开发的Google Fellow吴永辉博士,将成为Seed新的负责人,替换原LLM团队及Seed总负责人朱文佳,团队内部正在梳理调整汇报关系。

各位朋友们,激动人心的时刻终于到来!字节跳动的AI编程神器Trae今天(2025年2月17日)正式发布Windows版本了!作为第一批尝鲜者,我迫不及待地要和大家分享我的使用感受

还记得半年前在 X 上引起热议的肖像音频驱动技术 Loopy 吗?升级版技术方案来了,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman, 其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。
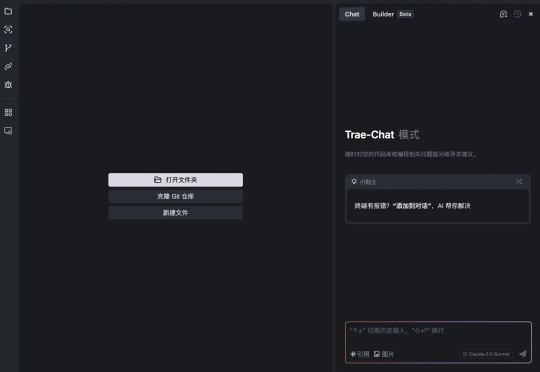
Cursor、Copilot、 Windsurf、Devin、Bolt.new 等一系列 AI 编程神器经常刷屏程序员圈。可惜,普遍对中文开发者不太友好,我把他们装好后,第一件事儿就是先折腾下汉化。而且时不时因为未知原因就被封号了。终于今天,字节跳动洞察到了这个痛点,发布了一款中文开发者友好的 AI IDE——Trae。虽然是海外版,但支持中文。