
GPT-5.6首批实测来了!精准狙击Mythos
GPT-5.6首批实测来了!精准狙击Mythos刚刚,Anthropic放出藏了俩月的大杀器——Claude Fable 5和Mythos 5,无异于扔下一枚炸弹。
来自主题: AI资讯
9591 点击 2026-06-10 16:07
 搜索
搜索
刚刚,Anthropic放出藏了俩月的大杀器——Claude Fable 5和Mythos 5,无异于扔下一枚炸弹。
Claude Fable 5 是今天 AI 领域的核心热点,这个「神话级」的模型性能表现非常卓越,吸引了无数眼球。

拆分后,字节仍将控股新公司,AI 制药核心团队、核心算法、技术平台和已有管线资产将整体进入新主体。
除此之外,context-mode 将大模型的记忆力从30分钟提升至 3 小时。
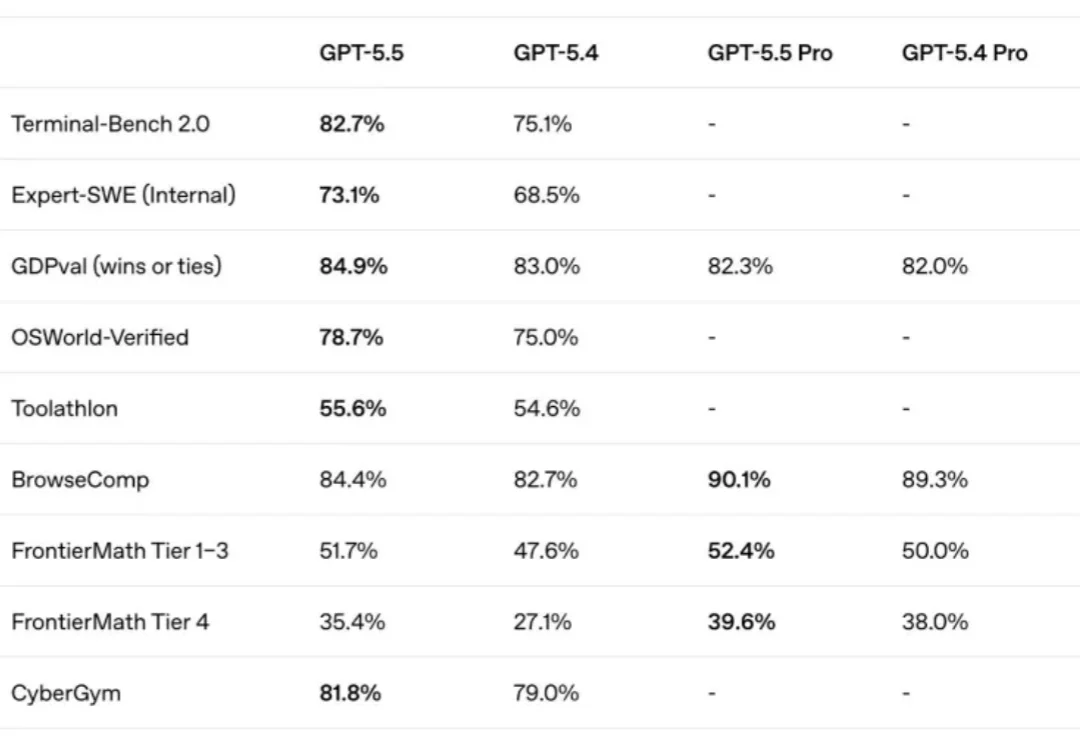
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。

对AI效率赛道,葬AI的朋友郭先生有一句名言:「效率赛道一定要做情绪价值,因为你会发现解决实际问题大家都不行。」
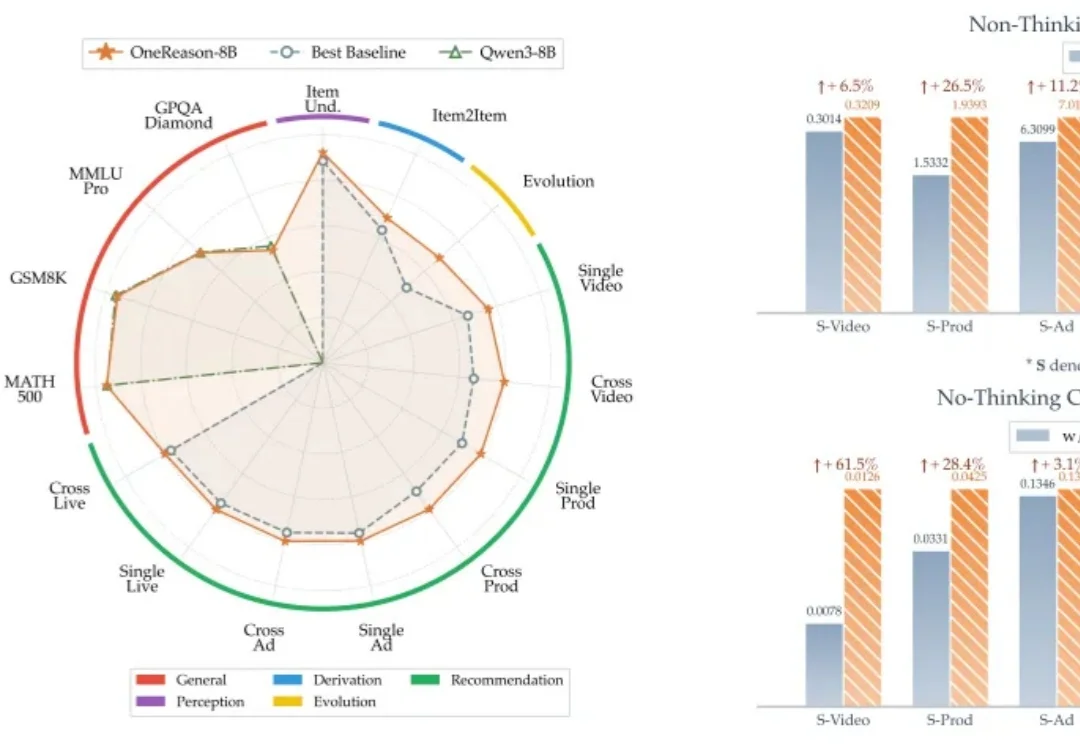
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
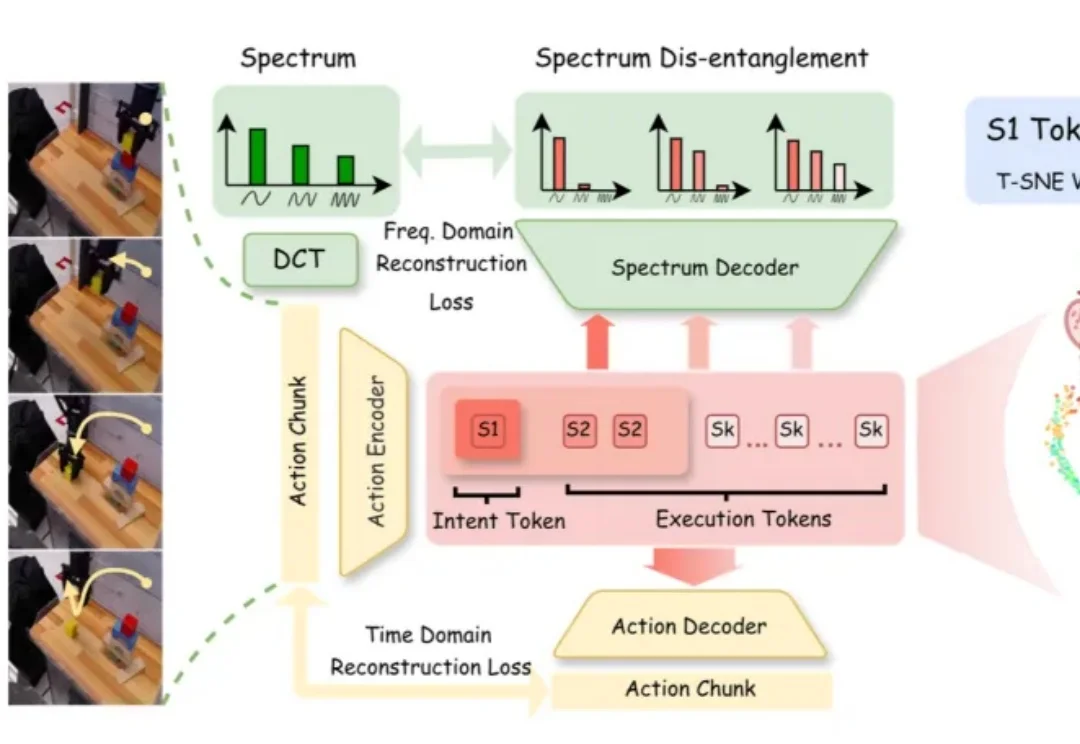
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。