
扎克伯格把自己“炼化”了
扎克伯格把自己“炼化”了他还在开发一个CEO智能体。
来自主题: AI资讯
8653 点击 2026-04-14 15:45
 搜索
搜索
他还在开发一个CEO智能体。

文本驱动的人体动作生成是游戏NPC、虚拟主播、机器人控制等实时交互系统的核心技术。

随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。
今天这篇文章,来分享一下我自己最近几个月高强度使用Agent之后,我自己总结出来的怎么给Agent设定规则,如何让它Agent更好的工作更聪明的一个非常重要的心得。

斯坦福「2026年AI指数报告」重磅出炉!这份432页长文含金量极高:中美AI巅峰对决,差距几乎抹平,缩减至仅2.7%。全球顶尖AI年产95个,基本都聚集在大厂。最残酷的是,22-25岁开发者的就业已被切掉20%。

太疯狂了!Meta和METR刚测出的AI进化数据,与中国团队两年前提出的「密度定律」完美重合。硅谷猛然回头,发现中国研究者在这条路上已领先两年!

Google DeepMind调查了一万个人,结果让整个AI安全评估体系汗颜:AI做了三倍多的「坏事」,但造成的实际伤害几乎一样。这意味着,我们现在用来证明AI安全的那套逻辑,可能从一开始就是错的。

一封内部备忘录,让 AI 行业最大的两家公司之间的战争,第一次有了清晰的文字记录。OpenAI 首席营收官 Denise Dresser 在本周日向全体员工发出了一份长达四页的战略备忘录。文件随后被外媒 The Verge 获取并公开全文。
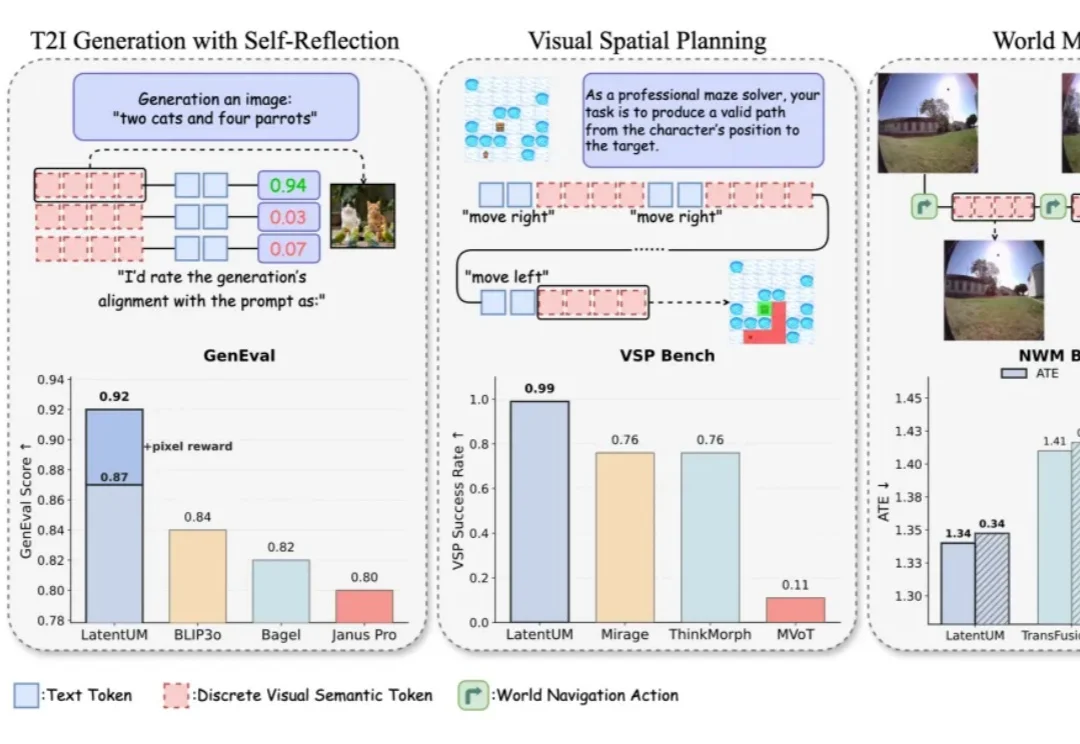
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。

办公室里,一排排工位整整齐齐,每个人对着屏幕敲敲打打,看起来和平常没什么两样。