
谷歌Gemma4-12B怎么用最好?16G显存轻薄本也能跑起本地多模态SubAgent
谷歌Gemma4-12B怎么用最好?16G显存轻薄本也能跑起本地多模态SubAgent过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
来自主题: AI技术研报
9726 点击 2026-06-11 10:18
 搜索
搜索
过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

“我无法将 AI 的能力与一成不变的经济模式调和!”

继 Step 3.5 Flash 后,阶跃星辰最近又推出新一代高效率 Flash 开源模型 ——Step 3.7 Flash。该模型最大特点就是多(模)、快(速)、好(用)、省(钱)。总参数 196B,采用稀疏 MoE 架构,推理激活参数仅 11B,配备 1.88B ViT 视觉编码器,推理速度最高 400 TPS,支持 256K 上下文。
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining
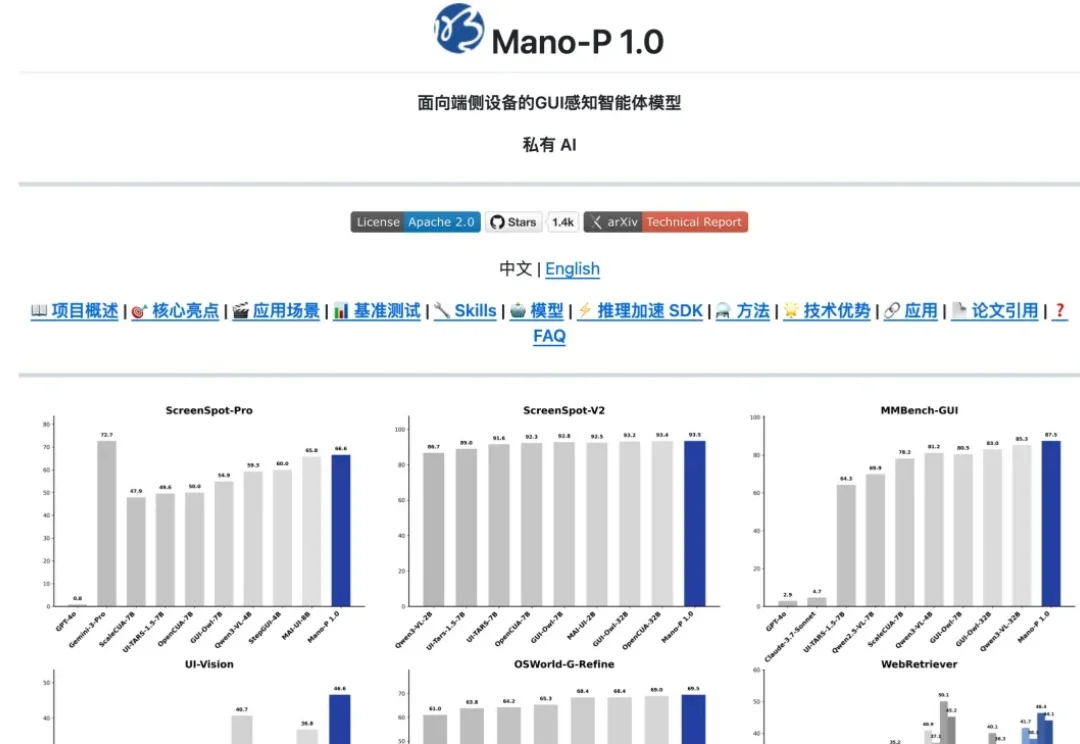
上次给大家分享了一个 CUA 的开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。反响还不错。
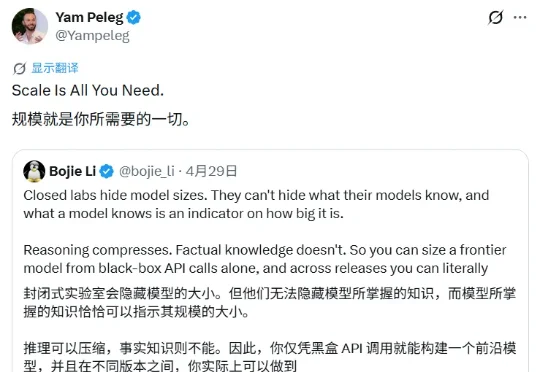
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

SenseNova U1 是商汤最新发布的一个开源的多模态模型,它的 Lite 系列 8B 和 A3B 参数版本,目前已经在 Hugging Face 和 GitHub 上开源。APPSO 也提前拿到了测试资格,我们发现商汤这款新一代原生理解生成统一模型,就开源模型来说,已经做到了最好水平。
刚刚,小米开源罗福莉带队研发的MiMo-V2.5系列模型,采用MIT协议,允许商用推理部署与二次训练,无需额外授权。此前,该系列模型于4月23日开启公测,包括MiMo-V2.5-Pro、MiMo-V2.5两款模型。模型具备更强Agent能力,支持100万上下文,且Token效率大幅提升。