9B端侧开源模型跑通百万上下文,面壁全新稀疏-线性混合注意力架构SALA立功了!
9B端侧开源模型跑通百万上下文,面壁全新稀疏-线性混合注意力架构SALA立功了!最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
来自主题: AI技术研报
11073 点击 2026-02-12 10:35
 搜索
搜索
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
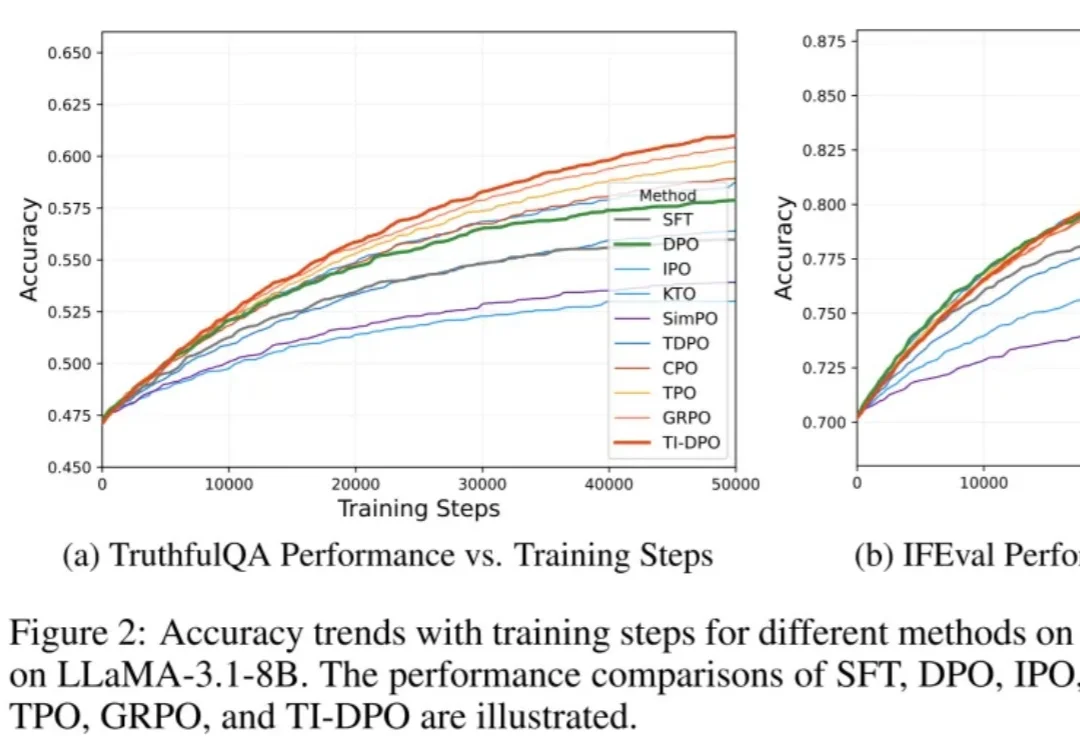
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

今日,阶跃星辰Step 3.5 Flash开源并上线,该模型在Agent场景和数学任务上能力逼近闭源模型,能够胜任复杂、长链条任务,是阶跃星辰迄今最强的开源基座模型。就在上周,阶跃星辰宣布由旷视科技联合创始人、千里科技董事长印奇正式出任董事长,并完成华勤、腾讯等参投的超50亿元B+轮融资。这也是印奇履新后,阶跃星辰在开源模型领域的首个大动作。
Clawdbot痛失本名改叫Moltbot后,热度丝毫不减。
大模型持续学习,又有新进展!

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。

OpenAI悄悄发布了翻译产品ChatGPT Translate,谷歌则祭出强势回应——TranslateGemma,一个能在手机上翻55种语言的开源模型。
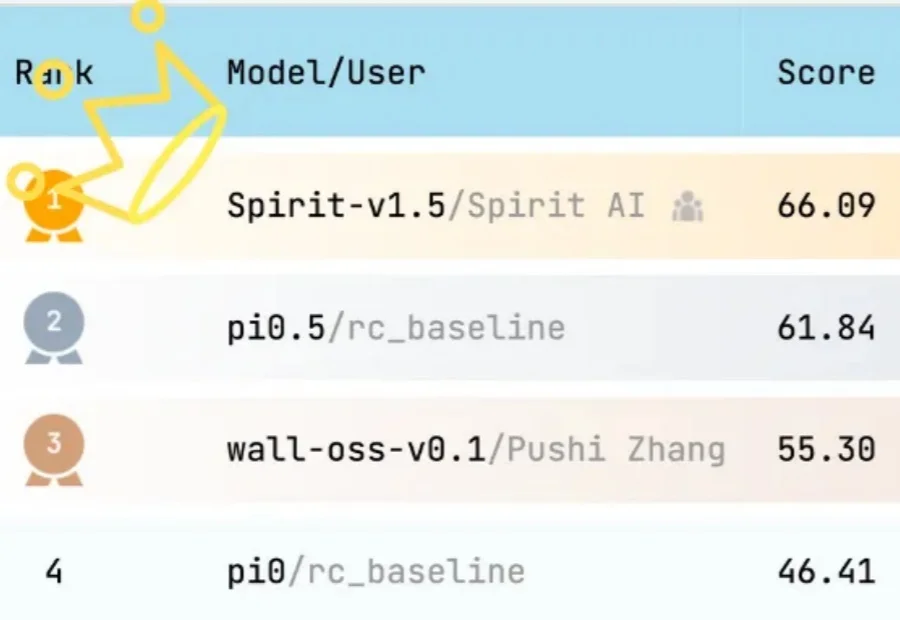
事情开始变得有趣起来了。
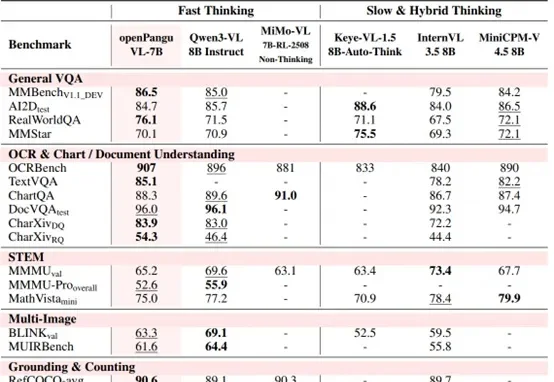
7B量级模型,向来是端侧部署与个人开发者的心头好。
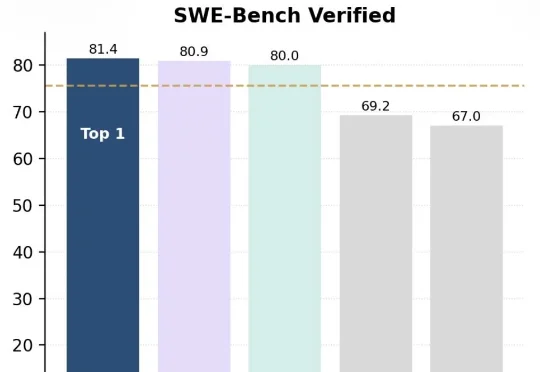
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。