让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
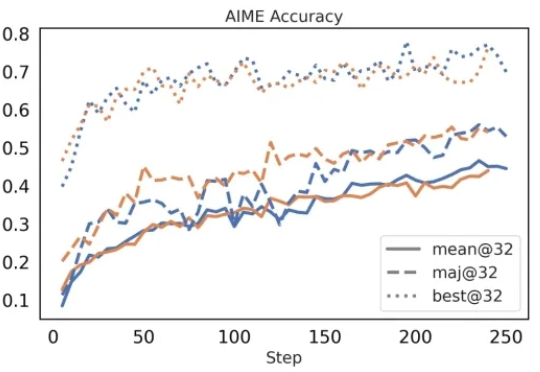
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
来自主题: AI技术研报
8968 点击 2025-08-13 11:27
 搜索
搜索
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
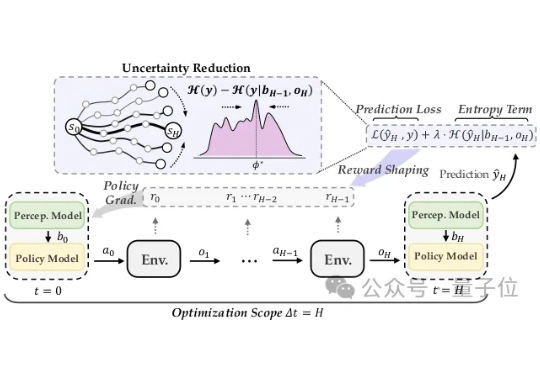
面对对抗攻击,具身智能体除了被动防范,也能主动出击! 在人类视觉系统启发下,清华朱军团队在TPMAI 2025中提出了强化学习驱动的主动防御框架REIN-EAD。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
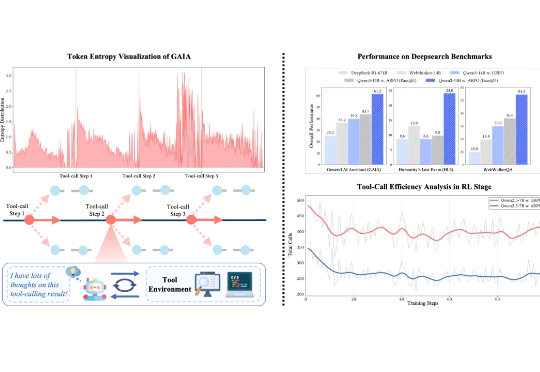
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
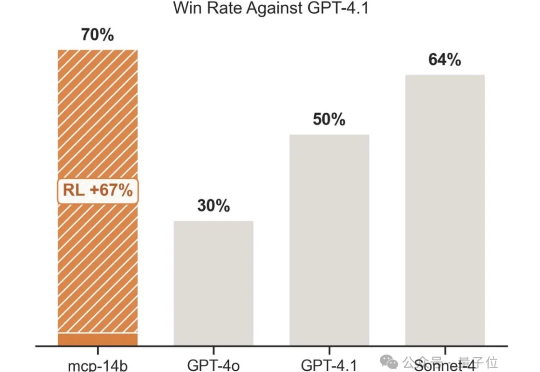
强化学习+任意一张牌,往往就是王炸。专注于LLM+RL的科技公司OpenPipe提出全新开源强化学习框架——MCP·RL。
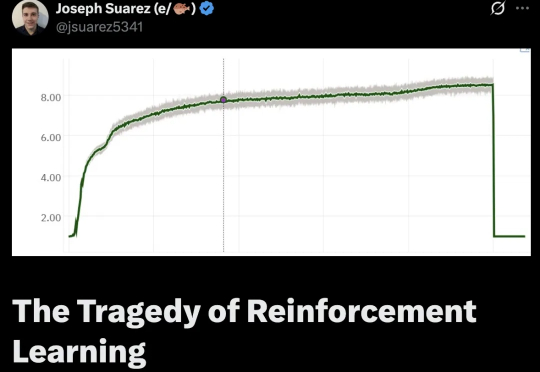
AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?
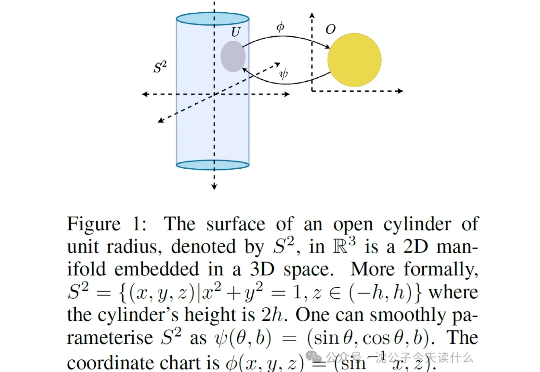
一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。